Prognózování založené na metodě exponenciálního vyhlazování. Příklad řešení problému
Jak předpovídat TEĎ! lepší model Exponenciální vyhlazování (ES) můžete vidět v grafu níže. Osa X je číslo produktu, osa Y je procentuální zlepšení kvality prognózy. Níže si přečtěte popis modelu, podrobný výzkum a výsledky experimentů.
Popis modelu
Metoda prognózování exponenciální vyhlazování je jedním z nejvíce jednoduchými způsoby prognózování. Předpověď lze získat pouze na jedno období dopředu. Pokud se prognóza provádí na dny, pak pouze jeden den dopředu, pokud týdny, pak jeden týden.
Pro srovnání, prognózy byly provedeny týden dopředu na 8 týdnů.
Co je to exponenciální vyhlazování?
Nechte řádek S představuje původní řadu prodejů pro prognózování
C(1)- prodej v prvním týdnu, S(2) ve druhém a tak dále.

Obrázek 1. Prodej podle týdne, řádek S
Stejně tak seriál S představuje exponenciálně vyhlazenou prodejní sérii. Koeficient α se pohybuje od nuly do jedné. Dopadá to následovně, zde t je časový okamžik (den, týden)
S (t+1) = S(t) + α *(С(t) - S(t))
Velké hodnoty vyhlazovací konstanty α urychlují odezvu prognózy na skok v pozorovaném procesu, ale mohou vést k nepředvídatelným odlehlým hodnotám, protože nedojde téměř k žádnému vyhlazování.
Poprvé po zahájení pozorování s pouze jedním výsledkem pozorování C (1) , když předpověď S (1) ne a stále není možné použít vzorec (1) jako předpověď S (2) měl by vzít C (1) .
Vzorec lze snadno přepsat do jiné formy:
S (t+1) = (1 -α )* S (t)+α * S (t).
S nárůstem vyhlazovací konstanty se tedy zvyšuje podíl nedávných prodejů a klesá podíl vyhlazených předchozích prodejů.
Konstanta α je vybrána experimentálně. Obvykle se pro různé konstanty vytvoří několik prognóz a z hlediska zvoleného kritéria se vybere nejoptimálnější konstanta.
Kritériem může být přesnost prognóz za předchozí období.
V naší studii jsme zvažovali modely exponenciálního vyhlazování, ve kterých α nabývá hodnot (0,2, 0,4, 0,6, 0,8). Pro srovnání s Předpovědí HNED! Pro každý produkt byly provedeny prognózy pro každé α a byla vybrána nejpřesnější předpověď. Ve skutečnosti by byla situace mnohem složitější, uživatel, aniž by předem znal přesnost předpovědi, se musí rozhodnout pro koeficient α, na kterém kvalita předpovědi velmi závisí. To je takový začarovaný kruh.
Jasně

Obrázek 2. α =0,2, stupeň exponenciálního vyhlazování je vysoký, reálné prodeje jsou špatně zohledněny

Obrázek 3. α =0,4, míra exponenciálního vyhlazování je průměrná, reálné tržby jsou brány v úvahu v průměrné míře
Můžete vidět, jak s rostoucí konstantou α vyhlazená série stále více odpovídá skutečným prodejům, a pokud existují odlehlé hodnoty nebo anomálie, dostaneme extrémně nepřesnou předpověď.

Obrázek 4. α =0,6, stupeň exponenciálního vyhlazování je nízký, reálné tržby jsou zohledněny výrazně
Vidíme, že při α=0,8 série téměř přesně opakuje tu původní, což znamená, že předpověď směřuje k pravidlu „prodá se stejné množství jako včera“
Stojí za zmínku, že zde je absolutně nemožné zaměřit se na chybu aproximace k původním údajům. Můžete dosáhnout dokonalého přizpůsobení, ale přesto dostanete nepřijatelnou předpověď.

Obrázek 5. α = 0,8, stupeň exponenciálního vyhlazování je extrémně nízký, reálné prodeje jsou silně zohledněny
Příklady předpovědí
Nyní se podívejme na předpovědi, které jsou získány pomocí různé významyα. Jak je vidět z obrázků 6 a 7, čím vyšší je koeficient vyhlazení, tím přesněji prognóza opakuje skutečné prodeje s jednokrokovým zpožděním. Takové zpoždění může být ve skutečnosti kritické, takže nemůžete jednoduše zvolit maximální hodnotu α. Jinak se dostaneme do situace, kdy řekneme, že se prodá přesně tolik, co se prodalo v předchozím období.

Obrázek 6. Predikce metody exponenciálního vyhlazování při α=0,2

Obrázek 7. Predikce metody exponenciálního vyhlazování při α=0,6
Podívejme se, co se stane, když α = 1,0. Připomeňme, že S je predikovaný (vyhlazený) prodej, C je skutečný prodej.
S (t+1) = (1 -α )* S (t)+α * S (t).
S (t+1) = S (t).
Tržby v den t+1 se dle prognózy rovnají tržbám předchozího dne. Proto je třeba k volbě konstanty přistupovat moudře.
Srovnání s Předpovědí HNED!
Nyní se podívejme na tuto metodu předpovědi ve srovnání s Forecast NOW!. Srovnání bylo provedeno na 256 produktech, které mají různé prodeje, s krátkodobou a dlouhodobou sezónností, se „špatnými“ prodejemi a nedostatky, akcemi a dalšími odlehlými hodnotami. Pro každý produkt byla sestavena předpověď pomocí modelu exponenciálního vyhlazování, pro různé α byla vybrána ta nejlepší a porovnána s prognózou pomocí modelu Forecast NOW!
V níže uvedené tabulce můžete vidět hodnotu předpovědi chyby pro každý produkt. Chyba zde byla považována za RMSE. Toto je kořen směrodatná odchylka předpověď z reality. Zhruba řečeno ukazuje, o kolik jednotek zboží jsme se odchýlili od prognózy. Zlepšení ukazuje, o jaké procento Předpověď HNED! Je lepší, když je číslo kladné, a horší, když je záporné. Na obrázku 8 osa X ukazuje produkty, osa Y ukazuje, jak moc je předpověď NOW! lepší než prognózování pomocí exponenciálního vyhlazování. Jak můžete vidět z tohoto grafu, přesnost předpovědí Forecast NOW! téměř vždy dvakrát vyšší a téměř nikdy horší. To ve skutečnosti znamená, že pomocí Forecast NOW! vám umožní snížit zásoby na polovinu nebo snížit manka.
Identifikace a analýza trendu časové řady se často provádí jejím zploštěním nebo vyhlazením. Exponenciální vyhlazování je jednou z nejjednodušších a nejběžnějších metod narovnání řady. Exponenciální vyhlazování lze reprezentovat jako filtr, jehož vstup je postupně přijímán z podmínek původní řady a výstup je tvořen aktuálními hodnotami exponenciálního průměru.
Nechť je časová řada.
Exponenciální vyhlazení řady se provádí pomocí opakujícího se vzorce: , .
Čím menší α, tím více se filtrují a potlačují výkyvy v původní sérii a šum.
Pokud budeme důsledně používat tento opakující se vztah, pak lze exponenciální průměr vyjádřit prostřednictvím hodnot časové řady X.
Pokud na začátku vyhlazování existují dřívější data, pak lze jako počáteční hodnotu použít aritmetický průměr všech dostupných dat nebo jejich část.
Poté, co se objevily práce R. Browna, se exponenciální vyhlazování často používá k řešení problému krátkodobého předpovídání časových řad.
Prohlášení o problému
Nechť je dána časová řada: .
Je nutné vyřešit problém prognózování časové řady, tzn. nalézt
Předpovědní horizont, to je nutné
Abychom zohlednili stárnutí dat, zavádíme nerostoucí posloupnost vah
Hnědý model
Předpokládejme, že D je malé (krátkodobá předpověď), pak k řešení takového problému použijeme Hnědý model.
Pokud vezmeme v úvahu prognózu o krok napřed, pak chyba této prognózy a nové prognózy je získána jako výsledek úpravy předchozí prognózy s přihlédnutím k její chybě - podstatě adaptace.
V krátkodobé prognóze je žádoucí co nejrychleji reflektovat nové změny a zároveň co nejlépe „očistit“ řadu od náhodných výkyvů. Že. váhu novějších pozorování je třeba zvýšit: .
Na druhou stranu, pro vyhlazení náhodných odchylek je třeba α snížit: .
Že. tyto dva požadavky jsou v rozporu. Hledání kompromisní hodnoty α představuje problém optimalizace modelu. Typicky se α bere z intervalu (0,1/3).
Příklady

Práce exponenciálního vyhlazování na α=0,2 na datech z měsíčních zpráv o prodeji zahraničních automobilových značek v Rusku za období od ledna 2007 do října 2008. Zaznamenejme prudké propady v lednu a únoru, kdy tržby tradičně klesají a rostou na začátek léta.
Problémy
Model funguje pouze pro krátký horizont předpovědi. Trend a sezónní změny se neberou v úvahu. Pro zohlednění jejich vlivu se navrhuje použít tyto modely: Holt (bere se v úvahu lineární trend), Holt-Winters (multiplikativní exponenciální trend a sezónnost), Theil-Wage (aditivní lineární trend a sezónnost).
9 5. Metoda exponenciálního vyhlazování. Výběr konstanty vyhlazování
Při použití metody nejmenších čtverců pro určení předpovědní tendence (trendu) se předem předpokládá, že všechna retrospektivní data (pozorování) mají stejný informační obsah. Logičtější by samozřejmě bylo vzít v úvahu proces diskontování výchozí informace, tedy nerovnost těchto dat pro vypracování prognózy. Toho je dosaženo v metodě exponenciálního vyhlazování tím, že nejnovější pozorování časové řady (tj. hodnoty bezprostředně předcházející předpovědnímu období prognózy) přidělují významnější „váhy“ ve srovnání s počátečními pozorováními. Mezi výhody metody exponenciálního vyhlazování patří také jednoduchost výpočetních operací a flexibilita popisu různé dynamiky procesů. Metoda našla největší uplatnění pro realizaci střednědobých prognóz.
5.1. Podstata metody exponenciálního vyhlazování
Podstatou metody je vyhlazování časových řad pomocí váženého „klouzavého průměru“, ve kterém se váhy řídí exponenciálním zákonem. Jinými slovy, čím dále od konce časové řady je bod, pro který je vážený klouzavý průměr počítán, tím menší „účast je třeba“ na vývoji prognózy.
Nechť se původní dynamická řada skládá z úrovní (složek řady) y t , t = 1 , 2 ,...,n . Pro každý m po sobě jdoucích úrovní této řady
(m dynamická řada s krokem rovným jedné. Pokud je m liché číslo a je vhodnější použít lichý počet úrovní, protože v tomto případě bude vypočítaná hodnota úrovně ve středu vyhlazovacího intervalu a může snadno nahradit skutečnou hodnotu, pak může následující vzorec zapsat k určení klouzavého průměru: t+ ξ t+ ξ ∑ yi ∑ yi i= t− ξ i= t− ξ 2ξ + 1 kde y t je klouzavá průměrná hodnota pro okamžik t (t = 1, 2,...,n) y i je skutečná hodnota hladiny v okamžiku i; i – pořadové číslo úrovně v intervalu vyhlazování. Hodnota ξ je určena z doby trvání vyhlazovacího intervalu. Od m = 2 ξ +1 pro liché m tedy ξ = m 2 − 1 . Výpočet klouzavého průměru s velkým počtem úrovní lze zjednodušit stanovením po sobě jdoucích hodnot klouzavého průměru rekurzivně: y t = y t− 1 + yt + ξ − y t − (ξ + 1 ) 2ξ + 1 Ale na základě skutečnosti, že je třeba přikládat větší „váhu“ nedávným pozorováním, klouzavý průměr potřebuje jinou interpretaci. Spočívá v tom, že hodnota získaná průměrováním nenahrazuje centrální člen intervalu průměrování, ale jeho poslední člen. Podle toho může být poslední výraz přepsán ve tvaru Mi = Mi + 1 y i− y i− m Zde je klouzavý průměr vztažený ke konci intervalu označen novým symbolem Mi. V podstatě se Mi rovná y t posunuté o ξ kroků doprava, to znamená, M i = y t + ξ, kde i = t + ξ. Vzhledem k tomu, že M i − 1 je odhad veličiny y i − m , výraz (5.1) lze přepsat do formuláře y i + 1 M i − 1 , Mi, definovaný výrazem (5.1). kde M i je odhad Pokud se výpočty (5.2) opakují, když přicházejí nové informace a přepsat ji do jiné formy, získáme vyhlazenou pozorovací funkci: Q i= α y i+ (1 − α ) Q i− 1, nebo v ekvivalentní formě Q t= α y t+ (1 − α ) Q t− 1 Výpočty provedené pomocí výrazu (5.3) s každým novým pozorováním se nazývají exponenciální vyhlazování. V posledním výrazu je pro odlišení exponenciálního vyhlazování od klouzavého průměru zaveden zápis Q namísto M. Množství α, které je analog m 1, se nazývá vyhlazovací konstanta. Hodnoty α leží v interval [0, 1]. Je-li α reprezentováno jako řada α + α(1 − α) + α(1 − α) 2 + α(1 − α) 3 + ... + α(1 − α) n , pak je snadné si všimnout, že „váhy“ klesají exponenciálně v čase. Například pro α = 0 dostaneme 2 0,2 + 0,16 + 0,128 + 0,102 + 0,082 + … Součet řady má tendenci k jednotě a členy součtu s časem klesají. Hodnota Q t ve výrazu (5.3) je exponenciální průměr prvního řádu, tedy průměr získaný přímo z vyhlazování pozorovaných dat (primární vyhlazování). Někdy je při vývoji statistických modelů užitečné uchýlit se k výpočtu exponenciálních průměrů vyššího řádu, tedy průměrů získaných opakovaným exponenciálním vyhlazováním. Obecný zápis v rekurentní formě pro exponenciální střední řád k je: Q t (k) = α Q t (k− 1 )+ (1 − α ) Q t (− k1 ). Hodnota k se mění v rozmezí 1, 2, ..., p,p+1, kde p je řád předpovědního polynomu (lineární, kvadratický atd.). Na základě tohoto vzorce pro exponenciální průměr prvního, druhého a třetího řádu byly získány následující výrazy: Q t (1 )= α y t + (1 − α ) Q t (− 1 1 ); Q t (2 )= α Q t (1 )+ (1 − α ) Q t (− 2 1 ); Q t (3 )= α Q t (2 )+ (1 − α ) Q t (− 3 1 ). 5.2. Stanovení parametrů předpovědního modelu metodou exponenciálního vyhlazování Je zřejmé, že pro vývoj hodnot prognózy na základě časové řady pomocí metody exponenciálního vyhlazování je nutné vypočítat koeficienty trendové rovnice pomocí exponenciálních průměrů. Odhady koeficientů jsou určeny pomocí základní Brown-Meyerovy věty, která spojuje koeficienty prediktivního polynomu s exponenciálními průměry odpovídajících řádů: (−
1
) aˆ p α (1 − α )∞ −α
)
j (p − 1 + j) ! ∑j p = 0 p! (k− 1) !j = 0 kde aˆ p jsou odhady koeficientů polynomu stupně. Koeficienty se zjistí řešením soustavy (p + 1) rovnic сp + 1 neznámý. Tedy pro lineární model aˆ 0 = 2 Q t (1 ) − Q t (2 ); aˆ 1 = 1 − α α (Q t (1 )− Q t (2 )); pro kvadratický model aˆ 0 = 3 (Q t (1 )− Q t (2 )) + Q t (3 ); aˆ 1 =1 − α α [ (6 −5 α ) Q t (1 ) −2 (5 −4 α ) Q t (2 ) +(4 −3 α ) Q t (3) ] ; aˆ 2 = (1 − α α ) 2 [ Q t (1 )− 2 Q t (2 )+ Q t (3 )] . Prognóza je realizována pomocí zvoleného polynomu, resp. pro lineární model ˆyt + τ = aˆ0 + aˆ1 τ ; pro kvadratický model ˆyt + τ = aˆ0 + aˆ1 τ + aˆ 2 2 τ 2, kde τ je krok predikce. Je třeba poznamenat, že exponenciální průměry Q t (k) lze vypočítat pouze se známým (zvoleným) parametrem, se znalostí počátečních podmínek Q 0 (k). Odhady počátečních podmínek, zejména pro lineární model Q(1)=a 1 − α Q(2 ) = a− 2 (1 − α ) a pro kvadratický model Q(1)=a 1 − α + (1 − α )(2 − α ) a 2(1− α) (1− α ) (3− 2α ) Q 0(2) = a 0- 2α 2 Q(3)=a 3(1− α) (1 − α ) (4 − 3 α ) a kde koeficienty a 0 a a 1 jsou vypočteny pomocí metody nejmenších čtverců. Hodnota vyhlazovacího parametru α je přibližně vypočtena vzorcem α ≈ m 2 + 1, kde m je počet pozorování (hodnot) v intervalu vyhlazování. Posloupnost výpočtu předpovědních hodnot je uvedena v Výpočet koeficientů řady metodou nejmenších čtverců Definování intervalu vyhlazování Výpočet vyhlazovací konstanty Výpočet počátečních podmínek Výpočet exponenciálních průměrů Výpočet odhadů a 0 , a 1 atd. Výpočet předpovědních hodnot řady Rýže. 5.1. Posloupnost výpočtu predikovaných hodnot Jako příklad uvažujme postup pro získání předpokládané hodnoty bezporuchového provozu výrobku, vyjádřené střední dobou mezi poruchami. Počáteční údaje jsou shrnuty v tabulce. 5.1. Lineární předpovědní model volíme ve tvaru y t = a 0 + a 1 τ Řešení je proveditelné s následujícími hodnotami počátečních veličin: a 0,0 = 64,2; a 1,0 = 31,5; a = 0,305. Tabulka 5.1. Počáteční údaje Číslo pozorování, t Délka kroku, předpověď, τ MTBF, y (hodina) S těmito hodnotami jsou vypočtené „vyhlazené“ koeficienty pro hodnoty y 2 budou stejné = α Q (1) - Q (2) = 97, 9; [ Q (1) - Q (2) 31,
9 , 1− α za počátečních podmínek 1 − α A 0, 0 - 1,0 = −7
,
6
1 − α = −79
,
4
a exponenciální průměry Q (1 ) = α y + (1 − α ) Q (1 ) 25,
2;
Q(2) = α Q (1) + (1 −α ) Q (2 ) = −47 , 5 . „Vyhlazená“ hodnota y 2 se vypočítá pomocí vzorce Qi (1) Qi (2) a 0,i a 1,i ˆyt Lineární předpovědní model má tedy tvar (tabulka 5.2). ˆy t + τ = 224,5+ 32τ . Vypočítejme předpokládané hodnoty pro průběžné doby 2 roky (τ = 1), 4 roky (τ = 2) a tak dále mezi poruchami produktu (tabulka 5.3). Tabulka 5.3. Předpovědní hodnotyˆy t Rovnice t+2 t+4 t+6 t+8 t+20 regrese (τ = 1) (τ = 2) (τ = 3) (τ = 5) τ =
ˆy t = 224,5+ 32τ Je třeba poznamenat, že celkovou „váhu“ posledních m hodnot časové řady lze vypočítat pomocí vzorce c = 1 − (m (− 1) m) . m+ 1 Takže pro poslední dvě pozorování řady (m = 2) je hodnota c = 1 − (2 2 − + 1 1) 2 = 0,667. 5.3. Výběr počátečních podmínek a určení vyhlazovací konstanty Jak vyplývá z výrazu Q t= α y t+ (1 − α ) Q t− 1, Při provádění exponenciálního vyhlazování je nutné znát počáteční (předchozí) hodnotu vyhlazované funkce. V některých případech lze první pozorování brát jako počáteční hodnotu častěji, počáteční podmínky jsou určeny podle výrazů (5.4) a (5.5). V tomto případě jsou hodnoty a 0, 0, a 1, 0 a a 2, 0 jsou určeny metodou nejmenších čtverců. Pokud nemáme velkou důvěru ve vybranou počáteční hodnotu, pak tím, že vezmeme velkou hodnotu vyhlazovací konstanty α až k pozorování, dostaneme „váha“ počáteční hodnoty k hodnotě (1 − α ) k<<
α
, и оно будет практически забыто. Наоборот, если мы уверены в правильности выбранного начального значения и неизменности модели в течение определенного отрезка времени в будущем,α
может быть выбрано малым (близким к 0). Volba vyhlazovací konstanty (nebo počtu pozorování v klouzavém průměru) tedy zahrnuje rozhodnutí o kompromisu. Typicky, jak ukazuje praxe, leží hodnota vyhlazovací konstanty v rozsahu od 0,01 do 0,3. Je známo několik přechodů, které umožňují najít přibližný odhad α. První vyplývá z podmínky rovnosti klouzavého a exponenciálního průměru α = m 2 + 1, kde m je počet pozorování v intervalu vyhlazování. Jiné přístupy jsou spojeny s přesností předpovědi. Je tedy možné určit α na základě Meyerova vztahu: α ≈ S y, kde S y – střední kvadratická chyba modelu; S 1 – střední kvadratická chyba původní řady. Použití posledně uvedeného vztahu je však komplikováno skutečností, že je velmi obtížné spolehlivě určit S y a S 1 z výchozí informace. Často parametr vyhlazování a zároveň koeficienty a 0, 0 a a 0, 1 jsou zvoleny optimální v závislosti na kritériu S 2 = α ∑ ∞ (1 − α ) j [ yij − ˆyij ] 2 → min j = 0 řešením algebraické soustavy rovnic, kterou získáme přirovnáním derivací k nule ∂S2 ∂S2 ∂S2 ∂a 0,0 ∂a 1,0 ∂a 2,0 Pro lineární prognostický model je tedy počáteční kritérium rovno S 2 = α ∑ ∞ (1 − α ) j [ yij − a0, 0 − a1, 0 τ ] 2 → min. j = 0 Řešení tohoto systému pomocí počítače nepředstavuje žádné potíže. Pro rozumnou volbu α můžete také použít postup zobecněného vyhlazování, který vám umožní získat následující vztahy spojující rozptyl prognózy a parametr vyhlazování pro lineární model: S p 2 ≈[ 1 + α β ] 2 [ 1 +4 β +5 β 2 +2 α (1 +3 β ) τ +2 α 2 τ 3 ] S y 2 pro kvadratický model Sp 2≈ [ 2 α + 3 α 3+ 3 α 2τ ] S y 2, kde β =
1
−
α
;Sy– RMS odchylka aproximace původní časové řady. Problémy s prognózami jsou založeny na změnách určitých údajů v čase (tržby, poptávka, zásoby, HDP, emise uhlíku, obyvatelstvo...) a promítání těchto změn do budoucnosti. Bohužel trendy identifikované z historických dat mohou být narušeny mnoha nepředvídatelnými okolnostmi. Data v budoucnu se tedy mohou výrazně lišit od toho, co se stalo v minulosti. To je problém předpovědi. Existují však techniky (nazývané exponenciální vyhlazování), které umožňují nejen pokusit se předpovídat budoucnost, ale také kvantifikovat nejistotu všeho, co je s prognózou spojeno. Numerické vyjádření nejistoty pomocí vytváření předpovědních intervalů je skutečně neocenitelné, ale v předpovědním světě často opomíjené. Stáhněte si poznámku ve formátu nebo formátu, příklady ve formátu Řekněme, že jste fanouškem „Pána prstenů“ a vyrábíte a prodáváte meče již tři roky (obr. 1). Zobrazme tržby graficky (obr. 2). Poptávka se za tři roky zdvojnásobila – možná je to trend? K této myšlence se vrátíme o něco později. Graf má několik vrcholů a údolí, což může být známkou sezónnosti. Konkrétně se vrcholy vyskytují v měsících očíslovaných 12, 24 a 36, což je prosinec. Ale možná je to jen náhoda? Pojďme to zjistit. Metody exponenciálního vyhlazování spoléhají na předpovídání budoucnosti z dat z minulosti, kde novější pozorování mají větší váhu než starší. Toto vážení je možné díky vyhlazovacím konstantám. První metoda exponenciálního vyhlazování, kterou vyzkoušíme, se nazývá jednoduché exponenciální vyhlazování (SES). Používá pouze jednu vyhlazovací konstantu. Jednoduché exponenciální vyhlazování předpokládá, že vaše data časové řady se skládají ze dvou složek: úrovně (nebo průměru) a nějaké chyby kolem této hodnoty. Neexistuje žádný trend ani sezónní výkyvy – prostě existuje hladina, kolem které poptávka kolísá, obklopená tu a tam malými chybami. Upřednostněním novějších pozorování může TEC způsobit posuny v této úrovni. V řeči vzorců, Poptávka v čase t = úroveň + náhodná chyba kolem úrovně v čase t Jak tedy zjistíte přibližnou hodnotu úrovně? Pokud připustíme, že všechny časové hodnoty mají stejnou hodnotu, měli bychom jednoduše vypočítat jejich průměrnou hodnotu. To je však špatný nápad. Větší váha by měla být věnována nedávným pozorováním. Vytvořme několik úrovní. Vypočítejme počáteční úroveň v prvním roce: úroveň 0 = průměrná poptávka za první rok (měsíce 1-12) Pro poptávku po mečích je to 163. Jako předpověď poptávky pro měsíc 1 používáme úroveň 0 (163). Poptávka v měsíci 1 je 165, což jsou 2 meče nad úrovní 0. Vyplatí se aktualizovat aproximaci základní linie. Rovnice pro jednoduché exponenciální vyhlazení je: úroveň 1 = úroveň 0 + několik procent × (poptávka 1 – úroveň 0) úroveň 2 = úroveň 1 + pár procent × (poptávka 2 – úroveň 1) Atd. „Několik procent“ se nazývá vyhlazovací konstanta a označuje se alfa. Může to být libovolné číslo od 0 do 100 % (0 až 1). Jak zvolit hodnotu alfa se naučíte později. Obecně platí, že hodnota pro různé časy je: Úroveň aktuální období = úroveň předchozí období + Budoucí poptávka se rovná poslední vypočtené úrovni (obr. 3). Protože nevíte, co je alfa, nastavte buňku C2 na 0,5 pro začátek. Po sestavení modelu najděte alfa takové, aby součet čtvercové chyby - E2 (nebo směrodatná odchylka - F2) byl minimální. Chcete-li to provést, spusťte volbu Hledání řešení. Chcete-li to provést, přejděte do nabídky DATA –> Hledání řešení a nainstalujte do okna Možnosti hledání řešení požadované hodnoty (obr. 4). Chcete-li zobrazit výsledky prognózy v grafu, nejprve vyberte rozsah A6:B41 a vytvořte jednoduchý spojnicový graf. Dále klikněte pravým tlačítkem na diagram a vyberte možnost Vyberte data. V okně, které se otevře, vytvořte druhý řádek a vložte do něj predikce z rozsahu A42:B53 (obr. 5). K otestování tohoto předpokladu stačí umístit lineární regresi na data poptávky a provést t test na vzestupu této trendové linie (jako v). Pokud je sklon přímky nenulový a statisticky významný (při testování pomocí Studentova t-testu je hodnota r méně než 0,05), data mají trend (obr. 6). Použili jsme funkci LINREGRESE, která vrací 10 popisných statistik (pokud jste tuto funkci dosud nepoužívali, doporučuji) a funkci INDEX, která umožňuje „vytáhnout“ pouze tři požadované statistiky, nikoli celou sadu. Ukázalo se, že sklon je 2,54 a je významný, protože Studentův test ukázal, že 0,000000012 je výrazně menší než 0,05. Trend tedy existuje a nezbývá než ho zahrnout do prognózy. Často se mu říká dvojité exponenciální vyhlazování, protože nemá jeden parametr vyhlazování – alfa, ale dva. Pokud má časová posloupnost lineární trend, pak: poptávka po čase t = úroveň + t × trend + náhodná odchylka úrovně v čase t Holt exponenciální vyhlazování s úpravou trendu má dvě nové rovnice, jednu pro úroveň, jak se pohybuje v čase, a druhou pro trend. Rovnice úrovně obsahuje vyhlazovací parametr alfa a rovnice trendu obsahuje gama. Takto vypadá nová rovnice úrovně: úroveň 1 = úroveň 0 + trend 0 + alfa × (poptávka 1 – (úroveň 0 + trend 0)) všimni si toho úroveň 0 + trend 0 je pouze jednokroková předpověď od počátečních hodnot do měsíce 1, takže poptávka 1 – (úroveň 0 + trend 0)- toto je jednokroková odchylka. Základní rovnice aproximace úrovně tedy bude: úroveň aktuální období = úroveň předchozí období + trend předchozí období + alfa × (poptávka aktuální období – (úroveň předchozí období) + trend předchozí období)) Rovnice aktualizace trendu: trend aktuálního období = trend předchozí období + gama × alfa × (poptávka aktuální období – (úroveň předchozí období) + trend předchozí období)) Holt vyhlazování v Excelu je podobné jednoduchému vyhlazování (obrázek 7) a stejně jako výše je cílem najít dva koeficienty a zároveň minimalizovat součet čtvercových chyb (obrázek 8). Chcete-li získat počáteční úroveň a hodnoty trendu (v buňkách C5 a D5 na obrázku 7), vykreslete graf pro prvních 18 měsíců prodeje a přidejte k němu trendovou linii s rovnicí. Zadejte počáteční hodnotu trendu 0,8369 a počáteční úroveň 155,88 do buněk C5 a D5. Předpovědní data lze prezentovat graficky (obr. 9). Rýže. 7. Holt exponenciální vyhlazování s úpravou trendu; Chcete-li obrázek zvětšit, klikněte na něj pravým tlačítkem a vyberte Otevřít obrázek na nové kartě Existuje způsob, jak otestovat sílu prediktivního modelu - porovnat chyby se sebou, posunuté o krok (nebo několik kroků). Pokud jsou odchylky náhodné, nelze model vylepšit. V datech poptávky však může být sezónní faktor. Koncept chybového termínu, který koreluje s verzí jiného období, se nazývá autokorelace (více o autokorelaci viz ). Chcete-li vypočítat autokorelaci, začněte s údaji o chybách prognózy pro každé období (sloupec F na obrázku 7 se přesune do sloupce B na obrázku 10). Dále určete průměrnou chybu předpovědi (obr. 10, buňka B39; vzorec v buňce: =PRŮMĚR(B3:B38)). Ve sloupci C vypočítejte odchylku chyby prognózy od průměru; vzorec v buňce C3: =B3-B$39. Dále posouvejte sloupec C o jeden sloupec doprava a o řádek dolů. Vzorce v buňkách D39: =SUMPRODUCT($C3:$C38,D3:D38), D41: =D39/$C39, D42: =2/SQRT(36), D43: =-2/SQRT(36). Co to znamená, že jeden ze sloupců D:O je „synchronní“ se sloupcem C Pokud jsou například sloupce C a D synchronní, pak číslo, které je v jednom z nich záporné, musí být v druhém kladné? v jednom pozitivní v příteli. To znamená, že součet součinů dvou sloupců bude významný (rozdíly se kumulují). Nebo, což je stejné, čím blíže je hodnota v rozsahu D41:O41 nule, tím nižší je korelace sloupce (od D do O) se sloupcem C (obr. 11). Jedna autokorelace je nad kritickou hodnotou. Chyba posunutá o rok koreluje sama se sebou. To znamená 12měsíční sezónní cyklus. A není se čemu divit. Pokud se podíváte na graf poptávky (obr. 2), ukazuje se, že každé Vánoce jsou vrcholy poptávky a v dubnu až květnu jsou nejnižší. Podívejme se na techniku předpovědi, která bere v úvahu sezónnost. Metoda se nazývá multiplikativní (z multiplikovat - násobit), protože používá násobení k zohlednění sezónnosti: Poptávka v čase t = (úroveň + t × trend) × sezónní očišťování pro čas t × jakékoli zbývající nepravidelné úpravy, které nemůžeme zohlednit Holt-Wintersovo vyhlazování se také nazývá trojité exponenciální vyhlazování, protože má tři parametry vyhlazování (alfa, gama a delta). Pokud například existuje 12měsíční sezónní cyklus: Předpověď pro měsíc 39 = (úroveň 36 + 3 × trend 36) x sezónnost 27 Při analýze dat je nutné zjistit, co je trend v datové řadě a co sezónnost. Chcete-li provádět výpočty pomocí Holt-Wintersovy metody, musíte: Začněte s nezpracovanými daty (sloupce A a B na obrázku 12) a přidejte sloupec C s vyhlazenými hodnotami klouzavého průměru. Protože sezónnost má 12měsíční cykly, má smysl používat 12měsíční průměr. S tímto průměrem je trochu problém. 12 je sudé číslo. Pokud vyrovnáte poptávku v měsíci 7, měli byste ji považovat za průměrnou poptávku z měsíců 1 až 12 nebo z měsíců 2 až 13? Chcete-li překonat tento problém, musíte vyhladit poptávku pomocí „klouzavého průměru 2x12“. To znamená, že vezměte polovinu ze dvou průměrů z měsíců 1 až 12 az měsíců 2 až 13. Vzorec v buňce C8: =(PRŮMĚR(B3:B14)+PRŮMĚR(B2:B13))/2. Vyhlazená data za měsíce 1–6 a 31–36 nelze získat, protože není k dispozici dostatek předchozích a následujících období. Pro názornost lze původní a vyhlazená data promítnout do diagramu (obr. 13). Nyní ve sloupci D vydělte původní hodnotu vyhlazenou hodnotou a získáte přibližnou hodnotu sezónního očištění (sloupec D na obr. 12). Vzorec v buňce D8 je =B8/C8. Všimněte si skoků o 20 % nad normální poptávku v měsících 12 a 24 (prosinec), zatímco na jaře jsou pozorovány poklesy. Tato technika vyhlazování vám poskytla dva bodové odhady pro každý měsíc (celkem 24 měsíců). Sloupec E najde průměr těchto dvou faktorů. Vzorec v buňce E1: =PRŮMĚR(D14,D26). Pro názornost lze úroveň sezónních výkyvů znázornit graficky (obr. 14). Nyní lze získat sezónně očištěná data. Vzorec v buňce G1 je: =B2/E2. Na základě údajů ve sloupci G sestrojte graf, doplňte jej spojnicí trendu, zobrazte na grafu rovnici trendu (obr. 15) a použijte koeficienty v následných výpočtech. Vytvořte nový list, jak je znázorněno na obr. 16. Dosaďte hodnoty v rozsahu E5:E16 z obr. 12 oblastí E2:E13. Vezměte hodnoty C16 a D16 z rovnice trendové čáry na obr. 15. Nastavte hodnoty vyhlazovacích konstant tak, aby začínaly na 0,5. Roztáhněte hodnoty na řádku 17 tak, aby pokryly rozsah měsíců 1 až 36. Spusťte Hledání řešení pro optimalizaci koeficientů vyhlazování (obr. 18). Vzorec v buňce B53 je: =(C$52+(A53-A$52)*D$52)*E41. Nyní je potřeba zkontrolovat autokorelace v provedené předpovědi (obr. 18). Vzhledem k tomu, že všechny hodnoty jsou umístěny mezi horní a dolní hranicí, chápete, že model odvedl dobrou práci při pochopení struktury hodnot poptávky. Máme tedy plně funkční předpověď. Jak nastavíte horní a dolní hranice, které lze použít k vytvoření realistických předpokladů? K tomu vám pomůže simulace Monte Carlo, se kterou jste se již setkali (viz také). Cílem je vytvořit budoucí scénáře chování poptávky a identifikovat skupinu, do které spadá 95 % z nich. Odstraňte předpověď z buněk B53:B64 z listu Excel (viz obr. 17). Poptávku tam zaznamenáte na základě simulace. Ten lze vygenerovat pomocí funkce NORMINV. Pro budoucí měsíce stačí dodat střední hodnotu (0), standardní rozdělení (10,37 z buňky $H$2) a náhodné číslo mezi 0 a 1. Funkce vrátí odchylku s pravděpodobností odpovídající zvonku křivka. Umístěte jednokrokovou simulaci chyb do buňky G53: =NORMIN(RAND(),0,H$2). Rozšiřte tento vzorec na G64 a získáte simulace chyb prognózy na 12 měsíců jednokrokové prognózy (obrázek 19). Vaše simulační hodnoty se budou lišit od hodnot zobrazených na obrázku (proto je to simulace!). S nejistotou prognózy máte vše, co potřebujete k aktualizaci úrovně, trendu a sezónního koeficientu. Vyberte tedy buňky C52:F52 a roztáhněte je na řádek 64. V důsledku toho máte simulovanou chybu prognózy a samotnou předpověď. Na základě opaku můžeme predikovat hodnoty poptávky. Do buňky B53 vložte vzorec: =F53+G53 a roztáhněte jej na B64 (obr. 20, rozsah B53:F64). Nyní můžete stisknout tlačítko F9 a předpověď pokaždé aktualizovat. Umístěte výsledky 1000 simulací do buněk A71:L1070, pokaždé transponujte hodnoty z rozsahu B53:B64 do rozsahu A71:L71, A72:L72, ... A1070:L1070. Pokud vám to vadí, napište nějaký kód VBA. Nyní máte 1000 scénářů pro každý měsíc a můžete použít funkci PERCENTILE k získání horní a dolní hranice uprostřed 95% intervalu spolehlivosti. V buňce A66 je vzorec: =PERCENTILE(A71:A1070,0,975) a v buňce A67: =PERCENTILE(A71:A1070,0,025). Jako obvykle lze pro přehlednost data prezentovat graficky (obr. 21). V grafu jsou dva zajímavé body: Napsáno podle knihy Johna Foremana. – M.: Alpina Publisher, 2016. – S. 329–381 Vývoj nových a analýza známých manažerských technologií, které mohou zlepšit efektivitu řízení podniku, se v současné době stává pro ruské podniky obzvláště důležitým. Jedním z nejoblíbenějších nástrojů je rozpočtový systém, který je založen na sestavení podnikového rozpočtu s následnou kontrolou plnění. Rozpočet představuje vyrovnané krátkodobé obchodní, výrobní, finanční a ekonomické plány rozvoje organizace. Podnikový rozpočet obsahuje cílové ukazatele, které jsou vypočítávány na základě prognózovaných dat. Nejvýznamnější prognózou při sestavování rozpočtu pro jakýkoli podnik je prognóza prodeje. V předchozích článcích byla provedena analýza aditivního a multiplikativního modelu a vypočten předpokládaný objem prodeje na následující období. Při analýze časových řad byla použita metoda klouzavého průměru, ve které jsou všechna data bez ohledu na období jejich výskytu stejná. Existuje další způsob, jak jsou datům přiřazeny váhy, přičemž novějším datům je přikládána větší váha než dřívějším datům. Metodu exponenciálního vyhlazování lze na rozdíl od metody klouzavého průměru použít také pro krátkodobé předpovědi budoucích trendů na jedno období dopředu a automaticky upraví jakoukoli předpověď ve světle rozdílů mezi skutečnými a předpokládanými výsledky. Proto má tato metoda oproti dříve diskutované jednoznačnou výhodu. Název metody pochází ze skutečnosti, že vytváří exponenciálně vážené klouzavé průměry za celou časovou řadu. Při exponenciálním vyhlazování se berou v úvahu všechna předchozí pozorování - předchozí je zohledněno s maximální váhou, předchozí s o něco menší váhou, nejranější pozorování ovlivňuje výsledek s minimální statistickou váhou. Algoritmus pro výpočet exponenciálně vyhlazených hodnot v libovolném bodě v řadě i je založen na třech veličinách: skutečná hodnota Ai v daném bodě v řadě i, Novou předpověď lze napsat takto: Výpočet exponenciálně vyhlazených hodnot
Při použití metody exponenciálního vyhlazování v praxi vyvstávají dva problémy: volba koeficientu vyhlazení (W), který významně ovlivňuje výsledky, a stanovení počáteční podmínky (Fi). Na jedné straně, aby se vyhladily náhodné odchylky, musí být hodnota snížena. Na druhou stranu pro zvýšení hmotnosti nových rozměrů je nutné zvýšit. I když v zásadě může W nabývat jakékoli hodnoty z rozsahu 0< W < 1, обычно ограничиваются интервалом от 0,2 до 0,5. При высоких значениях коэффициента сглаживания в большей степени учитываются мгновенные текущие наблюдения отклика (для динамично развивающихся фирм) и, наоборот, при низких его значениях сглаженная величина определяется в большей степени прошлой тенденцией развития, нежели текущим состоянием отклика системы (в условиях стабильного развития рынка). Volba vyhlazovací konstanty je subjektivní. Analytici ve většině společností používají při zpracování sérií své tradiční hodnoty W, podle zveřejněných údajů v analytickém oddělení Kodak tedy tradičně používají hodnotu 0,38 a ve Ford Motors - 0,28 nebo 0,3. Ruční výpočet exponenciálního vyhlazování vyžaduje extrémně velké množství monotónní práce. Na příkladu vypočítáme objem prognózy pro 13. čtvrtletí, pokud jsou k dispozici údaje o prodeji za posledních 12 čtvrtletí, pomocí jednoduché metody exponenciálního vyhlazování. Předpokládejme, že prognóza tržeb pro první čtvrtletí byla 3. A nechť koeficient vyhlazení W = 0,8. Vyplňte třetí sloupec v tabulce a za každé následující čtvrtletí dosaďte hodnotu předchozího pomocí vzorce: Pro 2. čtvrtletí F2 =0,8*4 (1-0,8)*3 =3,8 Obdobně se vyhlazená hodnota vypočítá pro koeficient 0,5 a 0,33. Prognóza objemu prodeje s W = 0,8 pro 13. čtvrtletí činila 13,3 tisíc rublů. Tyto údaje lze zobrazit v grafické podobě:


Počáteční údaje

Jednoduché exponenciální vyhlazování
alfa × (aktuální období poptávky – předchozí období na úrovni)


Možná máte trend

Holt exponenciální vyhlazování s úpravou trendu



Identifikace vzorců v datech


Holt-Wintersovo multiplikativní exponenciální vyhlazování







Vytvoření intervalu spolehlivosti pro prognózu



Ph.D., ředitel pro vědu a rozvoj JSC "KIS"
Metoda exponenciálního vyhlazování
předpověď v určitém bodě série Fi
nějaký předem stanovený koeficient vyhlazení W, konstantní v celé sérii.
Pro 3. čtvrtletí F3 =0,8*6 (1-0,8)*3,8 =5,6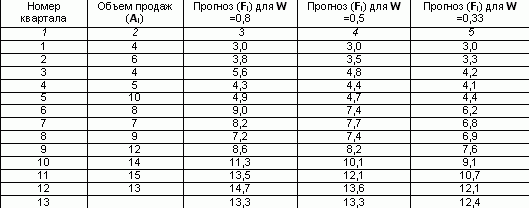
Výpočet prognózy objemu prodeje

Exponenciální vyhlazování



