Prognose basierend auf der Methode der exponentiellen Glättung. Beispiel einer Problemlösung
So prognostizieren Sie JETZT! besseres Modell Exponentielle Glättung (ES) können Sie in der Grafik unten sehen. Die X-Achse ist die Produktnummer, die Y-Achse die prozentuale Verbesserung der Prognosequalität. Nachfolgend finden Sie eine Beschreibung des Modells, detaillierte Untersuchungen und experimentelle Ergebnisse.
Modellbeschreibung
Prognosemethode exponentielle Glättung ist einer der meisten einfache Wege Prognose. Die Prognose kann nur für einen Zeitraum im Voraus eingeholt werden. Wenn die Vorhersage in Tagen erfolgt, dann nur einen Tag im Voraus; bei Wochen, dann eine Woche im Voraus.
Zum Vergleich wurde die Prognose für 8 Wochen eine Woche im Voraus durchgeführt.
Was ist exponentielle Glättung?
Lass die Reihe MIT stellt die ursprüngliche Umsatzreihe für die Prognose dar
C(1)- Verkäufe in der ersten Woche, MIT(2) im zweiten und so weiter.

Abbildung 1. Verkäufe nach Woche, Zeile MIT
Ebenso die Serie S stellt eine exponentiell geglättete Verkaufsreihe dar. Der Koeffizient α reicht von null bis eins. Es stellt sich wie folgt heraus, hier ist t ein Zeitpunkt (Tag, Woche)
S (t+1) = S(t) + α *(С(t) - S(t))
Große Werte der Glättungskonstante α beschleunigen die Reaktion der Prognose auf einen Sprung im beobachteten Prozess, können jedoch zu unvorhersehbaren Ausreißern führen, da nahezu keine Glättung erfolgt.
Zum ersten Mal nach Beginn der Beobachtungen mit nur einem Beobachtungsergebnis C (1) , wenn Prognose S (1) nein, und Formel (1) kann noch nicht als Prognose S verwendet werden (2) sollte C nehmen (1) .
Die Formel lässt sich leicht in eine andere Form umschreiben:
S (t+1) = (1 -α )* S (t)+α * MIT (T).
Mit einer Erhöhung der Glättungskonstante steigt also der Anteil der jüngsten Verkäufe und der Anteil der geglätteten früheren Verkäufe nimmt ab.
Die Konstante α wird experimentell ausgewählt. Typischerweise werden mehrere Prognosen für unterschiedliche Konstanten erstellt und die aus Sicht des gewählten Kriteriums optimalste Konstante ausgewählt.
Das Kriterium kann die Genauigkeit der Prognose für frühere Zeiträume sein.
In unserer Studie haben wir exponentielle Glättungsmodelle betrachtet, bei denen α Werte annimmt (0,2, 0,4, 0,6, 0,8). Zum Vergleich mit der Prognose JETZT! Für jedes Produkt wurden Prognosen für jedes α erstellt und die genaueste Prognose ausgewählt. In Wirklichkeit wäre die Situation viel komplizierter; der Benutzer muss sich, ohne die Genauigkeit der Prognose im Voraus zu kennen, für den Koeffizienten α entscheiden, von dem die Qualität der Prognose stark abhängt. Das ist so ein Teufelskreis.
Deutlich

Abbildung 2. α =0,2, der Grad der exponentiellen Glättung ist hoch, reale Umsätze werden kaum berücksichtigt

Abbildung 3. α =0,4, der Grad der exponentiellen Glättung ist durchschnittlich, reale Umsätze werden durchschnittlich berücksichtigt
Man erkennt, dass mit zunehmender Konstante α die geglättete Reihe zunehmend den realen Umsätzen entspricht und wir bei Ausreißern oder Anomalien eine äußerst ungenaue Prognose erhalten.

Abbildung 4. α =0,6, der Grad der exponentiellen Glättung ist gering, reale Umsätze werden maßgeblich berücksichtigt
Wir können sehen, dass sich die Reihe bei α=0,8 fast genau mit der ursprünglichen wiederholt, was bedeutet, dass die Prognose der Regel folgt: „Es wird die gleiche Menge verkauft wie gestern“.
Es ist erwähnenswert, dass es hier absolut unmöglich ist, sich auf den Fehler der Annäherung an die Originaldaten zu konzentrieren. Sie können eine perfekte Anpassung erzielen, erhalten aber dennoch eine inakzeptable Vorhersage.

Abbildung 5. α =0,8, der Grad der exponentiellen Glättung ist extrem niedrig, reale Umsätze werden stark berücksichtigt
Beispiele für Prognosen
Schauen wir uns nun die Vorhersagen an, die mit erhalten werden verschiedene Bedeutungenα. Wie aus den Abbildungen 6 und 7 ersichtlich ist, gilt: Je höher der Glättungskoeffizient, desto genauer wiederholt die Prognose die tatsächlichen Verkäufe mit einer Verzögerung von einem Schritt. Eine solche Verzögerung kann tatsächlich kritisch sein, sodass Sie nicht einfach den Maximalwert von α wählen können. Andernfalls kommt es zu einer Situation, in der wir sagen, dass genau so viel verkauft wird, wie in der Vorperiode verkauft wurde.

Abbildung 6. Vorhersage der exponentiellen Glättungsmethode bei α=0,2

Abbildung 7. Vorhersage der exponentiellen Glättungsmethode bei α=0,6
Mal sehen, was passiert, wenn α = 1,0. Erinnern wir uns daran, dass S prognostizierte (geglättete) Verkäufe und C reale Verkäufe sind.
S (t+1) = (1 -α )* S (t)+α * MIT (T).
S (t+1) = MIT (T).
Der Umsatz am Tag t+1 entspricht laut Prognose dem Umsatz am Vortag. Daher muss die Wahl der Konstante mit Bedacht angegangen werden.
Vergleich mit Prognose JETZT!
Schauen wir uns nun diese Prognosemethode im Vergleich zu Forecast NOW! an. Der Vergleich wurde an 256 Produkten durchgeführt, die unterschiedliche Verkäufe haben, mit kurz- und langfristiger Saisonalität, mit „schlechten“ Verkäufen und Engpässen, Werbeaktionen und anderen Ausreißern. Für jedes Produkt wurde eine Prognose mithilfe des exponentiellen Glättungsmodells erstellt, für verschiedene α wurde das beste ausgewählt und mit der Prognose mithilfe des Forecast NOW!-Modells verglichen.
In der folgenden Tabelle können Sie den prognostizierten Fehlerwert für jedes Produkt sehen. Der Fehler wurde hier als RMSE betrachtet. Dies ist die Wurzel von Standardabweichung Prognose aus der Realität. Grob gesagt zeigt es, um wie viele Wareneinheiten wir von der Prognose abgewichen sind. Die Verbesserung zeigt, um wie viel Prozent die Prognose JETZT! Es ist besser, wenn die Zahl positiv ist, und schlechter, wenn sie negativ ist. In Abbildung 8 zeigt die X-Achse Produkte, die Y-Achse gibt an, wie viel die Prognose JETZT! besser als die Prognose mit exponentieller Glättung. Wie Sie dieser Grafik entnehmen können, ist die Prognosegenauigkeit von Forecast NOW! fast immer doppelt so hoch und fast nie schlechter. Das bedeutet im Endeffekt, dass Sie mit Forecast NOW! ermöglicht es Ihnen, die Lagerbestände zu halbieren oder Engpässe zu reduzieren.
Das Erkennen und Analysieren des Trends einer Zeitreihe erfolgt häufig durch Abflachen oder Glätten. Die exponentielle Glättung ist eine der einfachsten und gebräuchlichsten Methoden zum Begradigen einer Reihe. Die exponentielle Glättung kann als Filter dargestellt werden, dessen Eingabe sequentiell aus den Termen der ursprünglichen Reihe empfangen wird und dessen Ausgabe durch die aktuellen Werte des exponentiellen Durchschnitts gebildet wird.
Sei eine Zeitreihe.
Die exponentielle Glättung der Reihe erfolgt nach der wiederkehrenden Formel: , .
Je kleiner α, desto stärker werden die Schwingungen der Originalreihe und das Rauschen gefiltert und unterdrückt.
Wenn wir diese wiederkehrende Beziehung konsequent verwenden, kann der exponentielle Durchschnitt durch die Werte der Zeitreihe X ausgedrückt werden.
Wenn zu Beginn der Glättung frühere Daten vorhanden sind, kann das arithmetische Mittel aller verfügbaren Daten oder ein Teil davon als Anfangswert verwendet werden.
Nach dem Erscheinen der Arbeiten von R. Brown wird die exponentielle Glättung häufig verwendet, um das Problem der kurzfristigen Vorhersage von Zeitreihen zu lösen.
Darstellung des Problems
Gegeben sei die Zeitreihe: .
Es ist notwendig, das Problem der Vorhersage einer Zeitreihe zu lösen, d.h. finden
Prognosehorizont, das ist notwendig
Um der Datenalterung Rechnung zu tragen, führen wir dann eine nicht ansteigende Folge von Gewichten ein
Braunes Modell
Nehmen wir an, dass D klein ist (Kurzfristprognose), dann verwenden wir zur Lösung eines solchen Problems Braunes Modell.
Wenn wir die Prognose einen Schritt voraus betrachten, dann ergibt sich der Fehler dieser Prognose und die neue Prognose als Ergebnis der Anpassung der vorherigen Prognose unter Berücksichtigung ihres Fehlers – das Wesen der Anpassung.
Bei der kurzfristigen Prognose ist es wünschenswert, neue Veränderungen möglichst schnell abzubilden und gleichzeitig die Reihe bestmöglich von zufälligen Schwankungen zu „reinigen“. Das. das Gewicht neuerer Beobachtungen sollte erhöht werden: .
Andererseits muss α reduziert werden, um zufällige Abweichungen auszugleichen: .
Das. Diese beiden Anforderungen stehen im Widerspruch. Das Finden eines Kompromisswerts von α stellt das Modelloptimierungsproblem dar. Typischerweise wird α aus dem Intervall (0,1/3) entnommen.
Beispiele

Die Arbeit der exponentiellen Glättung bei α=0,2 auf Daten aus monatlichen Berichten über Verkäufe ausländischer Automobilmarken in Russland für den Zeitraum von Januar 2007 bis Oktober 2008. Beachten wir starke Rückgänge im Januar und Februar, wenn die Verkäufe traditionell sinken und steigen Anfang des Sommers.
Probleme
Das Modell funktioniert nur für einen kurzen Prognosehorizont. Trend- und Saisonänderungen werden nicht berücksichtigt. Um ihren Einfluss zu berücksichtigen, wird vorgeschlagen, die folgenden Modelle zu verwenden: Holt (linearer Trend wird berücksichtigt), Holt-Winters (multiplikativer exponentieller Trend und Saisonalität), Theil-Wage (additiver linearer Trend und Saisonalität).
9 5. Exponentielle Glättungsmethode. Auswählen einer Glättungskonstante
Bei Verwendung der Methode kleinste Quadrate Zur Ermittlung der Prognosetendenz (Trend) wird vorab davon ausgegangen, dass alle retrospektiven Daten (Beobachtungen) den gleichen Informationsgehalt haben. Offensichtlich wäre es logischer, den Prozess der Diskontierung der Ausgangsinformationen, also der Ungleichheit dieser Daten, bei der Entwicklung einer Prognose zu berücksichtigen. Dies wird bei der exponentiellen Glättungsmethode erreicht, indem den neuesten Beobachtungen der Zeitreihe (d. h. den Werten unmittelbar vor der prognostizierten Vorlaufzeit) signifikantere „Gewichte“ im Vergleich zu den anfänglichen Beobachtungen gegeben werden. Zu den Vorteilen der exponentiellen Glättungsmethode gehören auch die Einfachheit der Rechenoperationen und die Flexibilität bei der Beschreibung verschiedener Prozessdynamiken. Die größte Anwendung findet die Methode bei der Umsetzung mittelfristiger Prognosen.
5.1. Die Essenz der exponentiellen Glättungsmethode
Der Kern der Methode besteht darin, dass die Zeitreihe mithilfe eines gewichteten „gleitenden Durchschnitts“ geglättet wird, bei dem die Gewichte dem Exponentialgesetz folgen. Mit anderen Worten: Je weiter vom Ende der Zeitreihe der Punkt entfernt ist, für den der gewichtete gleitende Durchschnitt berechnet wird, desto geringer ist die „Beteiligung“ an der Entwicklung der Prognose.
Die ursprüngliche dynamische Reihe bestehe aus Ebenen (Reihenkomponenten) y t , t = 1 , 2 ,...,n . Für jeweils m aufeinanderfolgende Ebenen dieser Reihe
(M dynamische Reihe mit einem Schritt gleich eins. Wenn m eine ungerade Zahl ist und es vorzuziehen ist, eine ungerade Anzahl von Stufen zu verwenden, da in diesem Fall der berechnete Stufenwert in der Mitte des Glättungsintervalls liegt und den tatsächlichen Wert leicht ersetzen kann, dann ist dies mit der folgenden Formel möglich geschrieben werden, um den gleitenden Durchschnitt zu bestimmen: t+ ξ t+ ξ ∑ yi ∑ yi i= t− ξ i= t− ξ 2ξ + 1 wobei y t der gleitende Durchschnittswert für den Moment t ist (t = 1, 2,...,n, y i der tatsächliche Wert des Niveaus im Moment i); i – Seriennummer der Ebene im Glättungsintervall. Der Wert von ξ wird aus der Dauer des Glättungsintervalls bestimmt. Seit m =2 ξ +1 für ungerades m also ξ = m 2 − 1 . Die Berechnung eines gleitenden Durchschnitts mit einer großen Anzahl von Ebenen kann vereinfacht werden, indem aufeinanderfolgende Werte des gleitenden Durchschnitts rekursiv ermittelt werden: y t= y t− 1 + yt + ξ − y t − (ξ + 1 ) 2ξ + 1 Aufgrund der Tatsache, dass den jüngsten Beobachtungen mehr „Gewicht“ beigemessen werden muss, muss der gleitende Durchschnitt jedoch anders interpretiert werden. Es liegt darin, dass der durch die Mittelung erhaltene Wert nicht den zentralen Term des Mittelungsintervalls, sondern dessen letzten Term ersetzt. Dementsprechend kann der letzte Ausdruck im Formular umgeschrieben werden Mi = Mi + 1 y i− y i− m Hier wird der gleitende Durchschnitt bezogen auf das Ende des Intervalls durch das neue Symbol M i angezeigt. Im Wesentlichen ist M i gleich y t, das um ξ Schritte nach rechts verschoben ist, d. h. M i = y t + ξ, wobei i = t + ξ. Wenn man bedenkt, dass M i − 1 eine Schätzung der Größe y i − m ist, gilt Ausdruck (5.1) kann im Formular umgeschrieben werden y i+ 1 M ich − 1 , M i , definiert durch Ausdruck (5.1). wobei M i die Schätzung ist Wenn die Berechnungen (5.2) wiederholt werden, sobald neue Informationen eintreffen und in eine andere Form umschreiben, erhalten wir eine geglättete Beobachtungsfunktion: Q i= α y i+ (1 − α ) Q i− 1 , oder in gleichwertiger Form Q t= α y t+ (1 − α ) Q t− 1 Berechnungen, die mit dem Ausdruck (5.3) bei jeder neuen Beobachtung durchgeführt werden, werden als exponentielle Glättung bezeichnet. Im letzten Ausdruck wird zur Unterscheidung der exponentiellen Glättung vom gleitenden Durchschnitt die Notation Q anstelle von M eingeführt. Die Menge α, die ist Analog zu m 1 wird die Glättungskonstante genannt. Die Werte von α liegen in Intervall [0, 1]. Wenn α als Reihe dargestellt wird α + α(1 − α) + α(1 − α) 2 + α(1 − α) 3 + ... + α(1 − α) n , Dann ist leicht zu erkennen, dass die „Gewichte“ mit der Zeit exponentiell abnehmen. Zum Beispiel erhalten wir für α = 0, 2 0,2 + 0,16 + 0,128 + 0,102 + 0,082 + … Die Summe der Reihen tendiert dazu, eins zu sein, und die Terme der Summe nehmen mit der Zeit ab. Der Wert von Q t in Ausdruck (5.3) ist der exponentielle Durchschnitt erster Ordnung, d. h. der direkt daraus erhaltene Durchschnitt Glättung von Beobachtungsdaten (primäre Glättung). Manchmal ist es bei der Entwicklung statistischer Modelle sinnvoll, auf die Berechnung exponentieller Durchschnittswerte höherer Ordnung zurückzugreifen, d. h. auf Durchschnittswerte, die durch wiederholte exponentielle Glättung erhalten werden. Die allgemeine Notation in wiederkehrender Form für die exponentielle Durchschnittsordnung k lautet: Q t (k)= α Q t (k− 1 )+ (1 − α ) Q t (− k1 ). Der Wert von k variiert innerhalb von 1, 2, ..., p, p+1, wobei p die Ordnung des Prognosepolynoms ist (linear, quadratisch usw.). Basierend auf dieser Formel für den exponentiellen Durchschnitt erster, zweiter und dritter Ordnung werden die Ausdrücke erhalten Q t (1 )= α y t + (1 − α ) Q t (− 1 1 ); Q t (2 )= α Q t (1 )+ (1 − α ) Q t (− 2 1 ); Q t (3 )= α Q t (2 )+ (1 − α ) Q t (− 3 1 ). 5.2. Bestimmung der Parameter des Prognosemodells mithilfe der Methode der exponentiellen Glättung Um Prognosewerte basierend auf einer Zeitreihe mit der Methode der exponentiellen Glättung zu entwickeln, ist es natürlich notwendig, die Koeffizienten der Trendgleichung mithilfe exponentieller Durchschnittswerte zu berechnen. Die Koeffizientenschätzungen werden mithilfe des grundlegenden Satzes von Brown-Meyer bestimmt, der die Koeffizienten des Vorhersagepolynoms mit exponentiellen Mittelwerten der entsprechenden Ordnungen verbindet: (−
1
) aˆ p α (1 − α )∞ −α
)
j (p − 1 + j ) ! ∑j p= 0 P! (k− 1 ) !j = 0 wobei aˆ p Schätzungen der Koeffizienten des Gradpolynoms sind. Die Koeffizienten werden durch Lösen des Gleichungssystems (p + 1) сp + 1 ermittelt unbekannt. Also für das lineare Modell aˆ 0 = 2 Q t (1 ) − Q t (2 ) ; aˆ 1 = 1 − α α (Q t (1 )− Q t (2 )) ; für quadratisches Modell aˆ 0 = 3 (Q t (1 )− Q t (2 )) + Q t (3 ); aˆ 1 =1 − α α [ (6 −5 α ) Q t (1 ) −2 (5 −4 α ) Q t (2 ) +(4 −3 α ) Q t (3 ) ] ; aˆ 2 = (1 − α α ) 2 [ Q t (1 )− 2 Q t (2 )+ Q t (3 )] . Die Prognose wird mit dem jeweils gewählten Polynom für das lineare Modell umgesetzt ˆyt + τ = aˆ0 + aˆ1 τ ; für quadratisches Modell ˆyt + τ = aˆ0 + aˆ1 τ + aˆ 2 2 τ 2 , wobei τ der Vorhersageschritt ist. Es ist zu beachten, dass exponentielle Durchschnittswerte Q t (k) nur mit einem bekannten (ausgewählten) Parameter berechnet werden können, wenn die Anfangsbedingungen Q 0 (k) bekannt sind. Schätzungen der Anfangsbedingungen, insbesondere für ein lineares Modell Q(1)=a 1 − α Q(2 ) = a− 2 (1 − α ) a für quadratisches Modell Q(1)=a 1 − α + (1 − α )(2 − α ) a 2(1− α ) (1− α )(3− 2α ) Q 0(2 ) = a 0− 2α 2 Q(3)=a 3(1− α ) (1 − α )(4 − 3 α ) a wobei die Koeffizienten a 0 und a 1 nach der Methode der kleinsten Quadrate berechnet werden. Der Wert des Glättungsparameters α wird näherungsweise durch die Formel berechnet α ≈ m 2 + 1, Dabei ist m die Anzahl der Beobachtungen (Werte) im Glättungsintervall. Der Ablauf der Berechnung der Prognosewerte ist in dargestellt Berechnung von Reihenkoeffizienten mit der Methode der kleinsten Quadrate Definieren des Glättungsintervalls Berechnung der Glättungskonstante Berechnung der Anfangsbedingungen Berechnung exponentieller Durchschnittswerte Berechnung der Schätzungen a 0 , a 1 usw. Berechnung von Prognosewerten einer Reihe Reis. 5.1. Reihenfolge der Berechnung der vorhergesagten Werte Betrachten Sie als Beispiel das Verfahren zur Ermittlung des vorhergesagten Wertes für den störungsfreien Betrieb eines Produkts, ausgedrückt durch die mittlere Zeit zwischen Ausfällen. Die Ausgangsdaten sind in der Tabelle zusammengefasst. 5.1. Wir wählen ein lineares Prognosemodell in der Form y t = a 0 + a 1 τ Die Lösung ist mit folgenden Werten der Anfangsgrößen machbar: a 0, 0 = 64, 2; a 1, 0 = 31, 5; α = 0,305. Tabelle 5.1. Ausgangsdaten Beobachtungsnummer, t Schrittlänge, Vorhersage, τ MTBF, y (Stunde) Mit diesen Werten werden die berechneten „geglätteten“ Koeffizienten für die Werte von y 2 werden gleich sein = α Q (1)− Q (2)= 97, 9; [ Q (1 )− Q (2 ) 31,
9 , 1− α bei Anfangsbedingungen 1 − α A 0 , 0 − eine 1, 0 = −7
,
6
1 − α = −79
,
4
und exponentielle Durchschnittswerte Q (1 )= α y + (1 − α ) Q (1 ) 25,
2;
F(2) = α Q (1) + (1 −α ) Q (2 ) = −47 . Der „geglättete“ Wert y 2 wird nach der Formel berechnet Qi(1) Qi(2) a 0 ,i a 1 ,i ˆyt Somit (Tabelle 5.2) hat das lineare Prognosemodell die Form ˆy t + τ = 224,5+ 32τ . Berechnen wir die vorhergesagten Werte für Durchlaufzeiten von 2 Jahren (τ = 1), 4 Jahren (τ = 2) usw. zwischen Produktausfällen (Tabelle 5.3). Tabelle 5.3. Prognosewerteˆy t Gleichung t+2 t+4 t+6 t+8 t+20 Rückschritt (τ = 1) (τ = 2) (τ = 3) (τ = 5) τ =
ˆy t = 224,5+ 32τ Zu beachten ist, dass sich mit der Formel das gesamte „Gewicht“ der letzten m Werte der Zeitreihe berechnen lässt c = 1 − (m (− 1 ) m ) . m+ 1 Für die letzten beiden Beobachtungen der Reihe (m = 2) beträgt der Wert c = 1 − (2 2 − + 1 1) 2 = 0,667. 5.3. Auswahl der Anfangsbedingungen und Bestimmung der Glättungskonstante Wie folgt aus dem Ausdruck Q t= α y t+ (1 − α ) Q t− 1 , Bei der Durchführung einer exponentiellen Glättung ist es notwendig, den anfänglichen (vorherigen) Wert der geglätteten Funktion zu kennen. In einigen Fällen kann die erste Beobachtung als Anfangswert verwendet werden; häufiger werden die Anfangsbedingungen gemäß den Ausdrücken (5.4) und (5.5) bestimmt. In diesem Fall sind die Werte a 0, 0,a 1, 0 und a 2 , 0 werden nach der Methode der kleinsten Quadrate bestimmt. Wenn wir nicht viel Vertrauen in den gewählten Anfangswert haben, erhalten wir, indem wir durch k Beobachtungen einen großen Wert der Glättungskonstante α nehmen „Gewicht“ des Anfangswertes zum Wert (1 − α ) k<<
α
, и оно будет практически забыто. Наоборот, если мы уверены в правильности выбранного начального значения и неизменности модели в течение определенного отрезка времени в будущем,α
может быть выбрано малым (близким к 0). Daher erfordert die Wahl einer Glättungskonstante (oder der Anzahl der Beobachtungen in einem gleitenden Durchschnitt) eine Kompromissentscheidung. Wie die Praxis zeigt, liegt der Wert der Glättungskonstante typischerweise im Bereich von 0,01 bis 0,3. Es sind mehrere Übergänge bekannt, die es ermöglichen, eine ungefähre Schätzung von α zu finden. Die erste folgt aus der Bedingung der Gleichheit der gleitenden und exponentiellen Durchschnitte α = m 2 + 1, Dabei ist m die Anzahl der Beobachtungen im Glättungsintervall. Andere Ansätze beziehen sich auf die Prognosegenauigkeit. Somit ist es möglich, α anhand der Meyer-Beziehung zu bestimmen: α ≈ S y, wobei S y – mittlerer quadratischer Fehler des Modells; S 1 – quadratischer Mittelwertfehler der Originalreihe. Die Verwendung der letztgenannten Beziehung wird jedoch dadurch erschwert, dass es sehr schwierig ist, S y und S 1 aus den Ausgangsinformationen zuverlässig zu bestimmen. Oft sind der Glättungsparameter und gleichzeitig die Koeffizienten a 0, 0 und a 0, 1 werden je nach Kriterium optimal ausgewählt S 2 = α ∑ ∞ (1 − α ) j [ yij − ˆyij ] 2 → min j= 0 durch Lösen eines algebraischen Gleichungssystems, das man durch Gleichsetzen der Ableitungen mit Null erhält ∂S2 ∂S2 ∂S2 ∂a 0, 0 ∂a 1, 0 ∂a 2, 0 Für ein lineares Prognosemodell ist das Anfangskriterium also gleich S 2 = α ∑ ∞ (1 − α ) j [ yij − a0 , 0 − a1 , 0 τ ] 2 → min. j= 0 Die Lösung dieses Systems mit einem Computer bereitet keine Schwierigkeiten. Um eine sinnvolle Wahl von α zu treffen, können Sie auch das verallgemeinerte Glättungsverfahren verwenden, mit dem Sie die folgenden Beziehungen erhalten können, die die Prognosevarianz und den Glättungsparameter für das lineare Modell verbinden: S p 2 ≈[ 1 + α β ] 2 [ 1 +4 β +5 β 2 +2 α (1 +3 β ) τ +2 α 2 τ 3 ] S y 2 für quadratisches Modell S p 2≈ [ 2 α + 3 α 3+ 3 α 2τ ] S y 2, wo β =
1
−
α
;Sj– RMS-Abweichung der Näherung der ursprünglichen Zeitreihe. Prognoseprobleme basieren auf Veränderungen bestimmter Daten im Laufe der Zeit (Umsatz, Nachfrage, Angebot, BIP, Kohlenstoffemissionen, Bevölkerung ...) und der Projektion dieser Veränderungen in die Zukunft. Leider können anhand historischer Daten ermittelte Trends durch viele unvorhergesehene Umstände gestört werden. Daher können die Daten in der Zukunft erheblich von denen in der Vergangenheit abweichen. Das ist das Problem der Prognose. Es gibt jedoch Techniken (exponentielle Glättung genannt), mit denen Sie nicht nur versuchen können, die Zukunft vorherzusagen, sondern auch die Unsicherheit aller mit der Prognose verbundenen Elemente zu quantifizieren. Der numerische Ausdruck von Unsicherheit durch die Erstellung von Prognoseintervallen ist wirklich von unschätzbarem Wert, wird jedoch in der Prognosewelt oft übersehen. Laden Sie die Notiz im oder Format herunter, Beispiele im Format Nehmen wir an, Sie sind ein Fan von „Der Herr der Ringe“ und stellen und verkaufen seit drei Jahren Schwerter (Abb. 1). Lassen Sie uns die Umsätze grafisch darstellen (Abb. 2). Die Nachfrage hat sich in drei Jahren verdoppelt – vielleicht ist das ein Trend? Wir werden etwas später auf diese Idee zurückkommen. Die Grafik weist mehrere Spitzen und Täler auf, was ein Zeichen für Saisonalität sein kann. Insbesondere treten die Spitzenwerte in den Monaten 12, 24 und 36 auf, also im Dezember. Aber vielleicht ist das nur ein Zufall? Finden wir es heraus. Exponentielle Glättungsmethoden basieren auf der Vorhersage der Zukunft anhand von Daten aus der Vergangenheit, wobei neuere Beobachtungen schwerer wiegen als ältere. Diese Gewichtung ist dank Glättungskonstanten möglich. Die erste exponentielle Glättungsmethode, die wir ausprobieren werden, heißt einfache exponentielle Glättung (SES). Es wird nur eine Glättungskonstante verwendet. Bei der einfachen exponentiellen Glättung wird davon ausgegangen, dass Ihre Zeitreihendaten aus zwei Komponenten bestehen: einem Niveau (oder Durchschnitt) und einem Fehler um diesen Wert. Es gibt keinen Trend oder saisonale Schwankungen – es gibt lediglich ein Niveau, um das die Nachfrage schwankt, das hier und da von kleinen Fehlern umgeben ist. Durch die Bevorzugung neuerer Beobachtungen kann TEC zu Verschiebungen dieses Niveaus führen. In der Sprache der Formeln Nachfrage zum Zeitpunkt t = Niveau + zufälliger Fehler um das Niveau zum Zeitpunkt t Wie ermitteln Sie also den ungefähren Pegelwert? Wenn wir annehmen, dass alle Zeitwerte den gleichen Wert haben, sollten wir einfach ihren Durchschnittswert berechnen. Dies ist jedoch eine schlechte Idee. Jüngsten Beobachtungen sollte mehr Gewicht beigemessen werden. Lassen Sie uns mehrere Ebenen erstellen. Berechnen wir das Ausgangsniveau im ersten Jahr: Stufe 0 = durchschnittlicher Bedarf für das erste Jahr (Monate 1-12) Für die Nachfrage nach Schwertern beträgt sie 163. Wir verwenden Level 0 (163) als Nachfrageprognose für Monat 1. Die Nachfrage für Monat 1 beträgt 165, d. h. sie liegt 2 Schwerter über Level 0. Es lohnt sich, die Basisnäherung zu aktualisieren. Die Gleichung für die einfache exponentielle Glättung lautet: Stufe 1 = Stufe 0 + ein paar Prozent × (Anforderung 1 – Stufe 0) Stufe 2 = Stufe 1 + ein paar Prozent × (Forderung 2 – Stufe 1) Usw. „Ein paar Prozent“ wird als Glättungskonstante bezeichnet und mit Alpha bezeichnet. Dies kann eine beliebige Zahl von 0 bis 100 % (0 bis 1) sein. Wie Sie den Alpha-Wert wählen, erfahren Sie später. Im Allgemeinen beträgt der Wert für verschiedene Zeiten: Ebene aktuelle Periode = Ebene vorherige Periode + Die zukünftige Nachfrage entspricht dem zuletzt berechneten Niveau (Abb. 3). Da Sie nicht wissen, was Alpha ist, setzen Sie Zelle C2 zunächst auf 0,5. Suchen Sie nach der Erstellung des Modells ein Alpha, bei dem die Summe des quadratischen Fehlers – E2 (oder der Standardabweichung – F2) minimal ist. Führen Sie dazu die Option aus Eine Lösung finden. Gehen Sie dazu durch das Menü DATEN –> Eine Lösung finden, und im Fenster installieren Lösungssuchoptionen erforderliche Werte (Abb. 4). Um die Prognoseergebnisse in einem Diagramm anzuzeigen, wählen Sie zunächst den Bereich A6:B41 aus und erstellen Sie ein einfaches Liniendiagramm. Klicken Sie anschließend mit der rechten Maustaste auf das Diagramm und wählen Sie die Option aus Daten auswählen. Erstellen Sie im sich öffnenden Fenster eine zweite Zeile und fügen Sie darin Vorhersagen aus dem Bereich A42:B53 ein (Abb. 5). Um diese Annahme zu testen, reicht es aus, eine lineare Regression an die Nachfragedaten anzupassen und einen t-Test für den Anstieg dieser Trendlinie durchzuführen (wie in). Wenn die Steigung der Linie ungleich Null und statistisch signifikant ist (beim Testen mit dem Student-t-Test, beträgt der Wert R kleiner als 0,05) weisen die Daten einen Trend auf (Abb. 6). Wir haben die LINEST-Funktion verwendet, die 10 beschreibende Statistiken zurückgibt (wenn Sie diese Funktion noch nicht verwendet haben, empfehle ich sie) und die INDEX-Funktion, mit der Sie nur die drei erforderlichen Statistiken und nicht den gesamten Satz „herausziehen“ können. Es stellte sich heraus, dass die Steigung 2,54 beträgt, und sie ist signifikant, da der Student-Test gezeigt hat, dass 0,000000012 deutlich kleiner als 0,05 ist. Es gibt also einen Trend, und es bleibt nur noch, ihn in die Prognose einzubeziehen. Sie wird oft als doppelte exponentielle Glättung bezeichnet, da sie nicht einen Glättungsparameter – Alpha, sondern zwei hat. Wenn eine Zeitsequenz einen linearen Trend aufweist, dann gilt: Bedarf für die Zeit t = Niveau + t × Trend + zufällige Niveauabweichung zum Zeitpunkt t Die exponentielle Holt-Glättung mit Trendanpassung verfügt über zwei neue Gleichungen, eine für den Pegel im Laufe der Zeit und eine für den Trend. Die Niveaugleichung enthält einen Glättungsparameter Alpha und die Trendgleichung enthält Gamma. So sieht die neue Niveaugleichung aus: Ebene 1 = Ebene 0 + Trend 0 + Alpha × (Nachfrage 1 – (Ebene 0 + Trend 0)) beachten Sie, dass Stufe 0 + Trend 0 ist nur eine einstufige Prognose von Anfangswerten bis Monat 1, also Nachfrage 1 – (Niveau 0 + Trend 0)- Dies ist eine einstufige Abweichung. Somit lautet die grundlegende Niveaunäherungsgleichung: Niveau aktuelle Periode = Niveau vorherige Periode + Trend vorherige Periode + Alpha × (Nachfrage aktuelle Periode – (Niveau vorherige Periode) + Trend vorherige Periode)) Trendaktualisierungsgleichung: Trend aktuelle Periode = Trend vorherige Periode + Gamma × Alpha × (Nachfrage aktuelle Periode – (Niveau vorherige Periode) + Trend vorherige Periode)) Die Holt-Glättung in Excel ähnelt der einfachen Glättung (Abbildung 7), und wie oben besteht das Ziel darin, zwei Koeffizienten zu finden und gleichzeitig die Summe der quadratischen Fehler zu minimieren (Abbildung 8). Um das Anfangsniveau und die Trendwerte (in den Zellen C5 und D5 in Abbildung 7) zu erhalten, zeichnen Sie ein Diagramm für die ersten 18 Verkaufsmonate und fügen Sie eine Trendlinie mit einer Gleichung hinzu. Geben Sie den anfänglichen Trendwert von 0,8369 und das anfängliche Niveau von 155,88 in die Zellen C5 und D5 ein. Prognosedaten können grafisch dargestellt werden (Abb. 9). Reis. 7. Exponentielle Holt-Glättung mit Trendanpassung; Um das Bild zu vergrößern, klicken Sie mit der rechten Maustaste darauf und wählen Sie es aus Bild in neuem Tab öffnen Es gibt eine Möglichkeit, die Stärke eines Vorhersagemodells zu testen: Vergleichen Sie die Fehler mit sich selbst, verschoben um einen Schritt (oder mehrere Schritte). Wenn die Abweichungen zufällig sind, kann das Modell nicht verbessert werden. Allerdings kann es bei den Nachfragedaten zu saisonalen Faktoren kommen. Das Konzept eines Fehlerterms, der mit der Version seiner selbst in einer anderen Periode korreliert, wird Autokorrelation genannt (weitere Informationen zur Autokorrelation finden Sie unter). Um die Autokorrelation zu berechnen, beginnen Sie mit den Prognosefehlerdaten für jeden Zeitraum (Spalte F in Abbildung 7 wechselt zu Spalte B in Abbildung 10). Bestimmen Sie als Nächstes den durchschnittlichen Prognosefehler (Abb. 10, Zelle B39; Formel in Zelle: =AVERAGE(B3:B38)). Berechnen Sie in Spalte C die Abweichung des Prognosefehlers vom Mittelwert; Formel in Zelle C3: =B3-B$39. Als nächstes verschieben Sie Spalte C nacheinander um eine Spalte nach rechts und eine Zeile nach unten. Formeln in den Zellen D39: =SUMPRODUCT($C3:$C38,D3:D38), D41: =D39/$C39, D42: =2/SQRT(36), D43: =-2/SQRT(36). Was bedeutet es, dass eine der D:O-Spalten „synchron“ mit Spalte C ist? Wenn beispielsweise die Spalten C und D synchron sind, muss eine Zahl, die in einer von ihnen negativ ist, in der anderen positiv sein in einem, positiv in Freund. Dies bedeutet, dass die Summe der Produkte der beiden Spalten signifikant ist (die Differenzen summieren sich). Oder, was dasselbe ist: Je näher der Wert im Bereich D41:O41 an Null liegt, desto geringer ist die Korrelation der Spalte (jeweils von D bis O) mit Spalte C (Abb. 11). Eine Autokorrelation liegt über dem kritischen Wert. Der um ein Jahr verschobene Fehler korreliert mit sich selbst. Dies bedeutet einen 12-monatigen Saisonzyklus. Und das ist nicht überraschend. Wenn Sie sich die Nachfragegrafik (Abb. 2) ansehen, stellt sich heraus, dass es jedes Jahr zu Weihnachten Spitzenwerte in der Nachfrage und im April-Mai Tiefpunkte gibt. Betrachten wir eine Prognosetechnik, die die Saisonalität berücksichtigt. Die Methode heißt multiplikativ (von multiplizieren – multiplizieren), da sie die Multiplikation verwendet, um die Saisonalität zu berücksichtigen: Nachfrage zum Zeitpunkt t = (Niveau + t × Trend) × saisonale Anpassung für den Zeitpunkt t × alle verbleibenden unregelmäßigen Anpassungen, die wir nicht berücksichtigen können Die Holt-Winters-Glättung wird auch als dreifache exponentielle Glättung bezeichnet, da sie über drei Glättungsparameter (Alpha, Gamma und Delta) verfügt. Wenn es beispielsweise einen 12-monatigen Saisonzyklus gibt: Prognose für Monat 39 = (Stufe 36 + 3 × Trend 36) x Saisonalität 27 Bei der Datenanalyse ist es notwendig herauszufinden, was ein Trend in einer Datenreihe und was Saisonalität ist. Um Berechnungen mit der Holt-Winters-Methode durchzuführen, müssen Sie: Beginnen Sie mit den Rohdaten (Spalten A und B in Abbildung 12) und fügen Sie Spalte C mit den geglätteten Werten des gleitenden Durchschnitts hinzu. Da die Saisonalität 12-Monats-Zyklen aufweist, ist es sinnvoll, einen 12-Monats-Durchschnitt zu verwenden. Es gibt ein kleines Problem mit diesem Durchschnitt. 12 ist eine gerade Zahl. Wenn Sie die Nachfrage für Monat 7 glätten, sollten Sie davon ausgehen, dass es sich um die durchschnittliche Nachfrage der Monate 1 bis 12 oder der Monate 2 bis 13 handelt? Um diese Schwierigkeit zu überwinden, müssen Sie die Nachfrage mithilfe eines „gleitenden 2x12-Durchschnitts“ glätten. Nehmen Sie also die Hälfte der beiden Durchschnittswerte von Monat 1 bis 12 und von Monat 2 bis 13. Die Formel in Zelle C8: =(DURCHSCHNITT(B3:B14)+DURCHSCHNITT(B2:B13))/2. Für die Monate 1–6 und 31–36 können keine geglätteten Daten ermittelt werden, da nicht genügend Vor- und Folgeperioden vorhanden sind. Der Übersichtlichkeit halber können die ursprünglichen und geglätteten Daten im Diagramm wiedergegeben werden (Abb. 13). Teilen Sie nun in Spalte D den ursprünglichen Wert durch den geglätteten Wert und erhalten Sie den ungefähren saisonalen Anpassungswert (Spalte D in Abb. 12). Die Formel in Zelle D8 lautet =B8/C8. Beachten Sie die Spitzen von 20 % über der normalen Nachfrage in den Monaten 12 und 24 (Dezember), während im Frühjahr Tiefststände zu beobachten sind. Mit dieser Glättungstechnik erhielten Sie zwei Punktschätzungen für jeden Monat (insgesamt 24 Monate). Spalte E ermittelt den Durchschnitt dieser beiden Faktoren. Formel in Zelle E1: =AVERAGE(D14,D26). Der Übersichtlichkeit halber kann die Höhe der saisonalen Schwankungen grafisch dargestellt werden (Abb. 14). Ab sofort können saisonbereinigte Daten abgerufen werden. Die Formel in Zelle G1 lautet: =B2/E2. Erstellen Sie ein Diagramm basierend auf den Daten in Spalte G, ergänzen Sie es mit einer Trendlinie, zeigen Sie die Trendgleichung im Diagramm an (Abb. 15) und verwenden Sie die Koeffizienten in nachfolgenden Berechnungen. Bilden Sie ein neues Blatt wie in Abb. 16. Ersetzen Sie die Werte im Bereich E5:E16 aus Abb. 12 Bereiche E2:E13. Entnehmen Sie die Werte von C16 und D16 der Trendliniengleichung in Abb. 15. Stellen Sie die Werte der Glättungskonstanten so ein, dass sie bei 0,5 beginnen. Erweitern Sie die Werte in Zeile 17, um den Bereich der Monate 1 bis 36 abzudecken. Führen Sie aus Eine Lösung finden zur Optimierung der Glättungskoeffizienten (Abb. 18). Die Formel in Zelle B53 lautet: =(C$52+(A53-A$52)*D$52)*E41. Jetzt müssen Sie die Autokorrelationen in der erstellten Prognose überprüfen (Abb. 18). Da alle Werte zwischen der oberen und unteren Grenze liegen, verstehen Sie, dass das Modell gute Arbeit beim Verständnis der Struktur der Nachfragewerte geleistet hat. Wir haben also eine völlig funktionierende Prognose. Wie legen Sie Ober- und Untergrenzen fest, anhand derer realistische Annahmen getroffen werden können? Dabei hilft Ihnen die Monte-Carlo-Simulation, die Sie bereits kennengelernt haben (siehe auch). Die Idee besteht darin, zukünftige Szenarien des Nachfrageverhaltens zu erstellen und die Gruppe zu identifizieren, zu der 95 % von ihnen gehören. Entfernen Sie die Prognose aus den Zellen B53:B64 aus der Excel-Tabelle (siehe Abb. 17). Dort erfassen Sie den Bedarf auf Basis der Simulation. Letzteres kann mit der Funktion NORMINV generiert werden. Für zukünftige Monate müssen Sie lediglich den Mittelwert (0), die Standardverteilung (10,37 aus Zelle $H$2) und eine Zufallszahl zwischen 0 und 1 angeben. Die Funktion gibt die Abweichung mit einer Wahrscheinlichkeit zurück, die einer Glocke entspricht Kurve. Platzieren Sie die einstufige Fehlersimulation in Zelle G53: =NORMIN(RAND(),0,H$2). Wenn Sie diese Formel auf G64 erweitern, erhalten Sie Prognosefehlersimulationen für 12 Monate einer einstufigen Prognose (Abbildung 19). Ihre Simulationswerte werden von den in der Abbildung gezeigten abweichen (deshalb handelt es sich um eine Simulation!). Mit der Prognoseunsicherheit haben Sie alles, was Sie brauchen, um Niveau, Trend und Saisonkoeffizienten zu aktualisieren. Wählen Sie also die Zellen C52:F52 aus und strecken Sie sie bis zur Zeile 64. Als Ergebnis haben Sie einen simulierten Prognosefehler und die Prognose selbst. Auf der Grundlage des Gegenteils können wir Nachfragewerte vorhersagen. Fügen Sie die Formel in Zelle B53 ein: =F53+G53 und strecken Sie sie bis B64 (Abb. 20, Bereich B53:F64). Jetzt können Sie die Taste F9 drücken und so die Prognose jedes Mal aktualisieren. Platzieren Sie die Ergebnisse von 1000 Simulationen in den Zellen A71:L1070 und übertragen Sie jedes Mal die Werte aus dem Bereich B53:B64 in den Bereich A71:L71, A72:L72, ... A1070:L1070. Wenn Sie das stört, schreiben Sie VBA-Code. Jetzt haben Sie 1000 Szenarien für jeden Monat und können die PERCENTILE-Funktion verwenden, um die Ober- und Untergrenzen in der Mitte des 95 %-Konfidenzintervalls zu ermitteln. In Zelle A66 lautet die Formel: =PERCENTILE(A71:A1070,0,975) und in Zelle A67: =PERCENTILE(A71:A1070,0,025). Der Übersichtlichkeit halber können die Daten wie gewohnt grafisch dargestellt werden (Abb. 21). Es gibt zwei interessante Punkte in der Grafik: Geschrieben nach dem Buch von John Foreman. – M.: Alpina Verlag, 2016. – S. 329–381 Die Entwicklung neuer und die Analyse bekannter Managementtechnologien, die die Effizienz der Unternehmensführung verbessern können, werden derzeit für russische Unternehmen besonders relevant. Eines der beliebtesten Instrumente ist das Budgetierungssystem, das auf der Erstellung eines Unternehmensbudgets mit anschließender Kontrolle der Ausführung basiert. Das Budget stellt ausgewogene kurzfristige Handels-, Produktions-, Finanz- und Wirtschaftspläne für die Entwicklung der Organisation dar. Das Unternehmensbudget enthält Ziele, die auf Basis von Prognosedaten berechnet werden. Die wichtigste Prognose bei der Budgeterstellung für jedes Unternehmen ist die Umsatzprognose. In früheren Artikeln wurde eine Analyse des additiven und multiplikativen Modells durchgeführt und das prognostizierte Verkaufsvolumen für die folgenden Zeiträume berechnet. Bei der Analyse von Zeitreihen wurde die Methode des gleitenden Durchschnitts verwendet, bei der alle Daten, unabhängig vom Zeitraum ihres Auftretens, gleich sind. Es gibt eine andere Möglichkeit, Daten Gewichtungen zuzuweisen, wobei neueren Daten mehr Gewicht beigemessen wird als früheren Daten. Die Methode der exponentiellen Glättung kann im Gegensatz zur Methode des gleitenden Durchschnitts auch für kurzfristige Prognosen zukünftiger Trends einen Zeitraum im Voraus verwendet werden und passt jede Prognose automatisch an, wenn Unterschiede zwischen den tatsächlichen und den prognostizierten Ergebnissen auftreten. Deshalb hat die Methode einen klaren Vorteil gegenüber der zuvor besprochenen. Der Name der Methode rührt daher, dass sie exponentiell gewichtete gleitende Durchschnitte über die gesamte Zeitreihe erzeugt. Bei der exponentiellen Glättung werden alle vorherigen Beobachtungen berücksichtigt – die vorherige wird mit maximalem Gewicht berücksichtigt, die davorliegende mit etwas geringerem Gewicht, die früheste Beobachtung beeinflusst das Ergebnis mit minimalem statistischem Gewicht. Der Algorithmus zur Berechnung exponentiell geglätteter Werte an jedem Punkt der Reihe i basiert auf drei Größen: tatsächlicher Wert von Ai an einem bestimmten Punkt in der Reihe i, Die neue Prognose kann wie folgt geschrieben werden: Berechnung exponentiell geglätteter Werte
Bei der praktischen Anwendung des exponentiellen Glättungsverfahrens treten zwei Probleme auf: die Wahl des Glättungskoeffizienten (W), der die Ergebnisse maßgeblich beeinflusst, und die Bestimmung der Anfangsbedingung (Fi). Um zufällige Abweichungen auszugleichen, muss einerseits der Wert reduziert werden. Um andererseits das Gewicht neuer Dimensionen zu erhöhen, ist es notwendig, es zu erhöhen. Allerdings kann W grundsätzlich jeden Wert aus dem Bereich 0 annehmen< W < 1, обычно ограничиваются интервалом от 0,2 до 0,5. При высоких значениях коэффициента сглаживания в большей степени учитываются мгновенные текущие наблюдения отклика (для динамично развивающихся фирм) и, наоборот, при низких его значениях сглаженная величина определяется в большей степени прошлой тенденцией развития, нежели текущим состоянием отклика системы (в условиях стабильного развития рынка). Die Wahl der Glättungskonstante ist subjektiv. Analysten der meisten Unternehmen verwenden bei der Verarbeitung von Serien ihre traditionellen W-Werte. So verwenden sie laut veröffentlichten Daten in der Analyseabteilung von Kodak traditionell einen Wert von 0,38 und bei Ford Motors - 0,28 oder 0,3. Die manuelle Berechnung der exponentiellen Glättung erfordert einen extrem hohen monotonen Arbeitsaufwand. Anhand des Beispiels berechnen wir das prognostizierte Volumen für das 13. Quartal, wenn Umsatzdaten für die letzten 12 Quartale verfügbar sind, und verwenden dabei die einfache Methode der exponentiellen Glättung. Nehmen wir an, dass die Umsatzprognose für das erste Quartal 3 war. Und sei der Glättungskoeffizient W = 0,8. Füllen wir die dritte Spalte der Tabelle aus und ersetzen wir für jedes weitere Quartal den Wert des vorherigen Quartals mithilfe der Formel: Für das 2. Viertel F2 =0,8*4 (1-0,8)*3 =3,8 Ebenso wird der geglättete Wert für die Koeffizienten 0,5 und 0,33 berechnet. Die Prognose für das Verkaufsvolumen mit W = 0,8 für das 13. Quartal belief sich auf 13,3 Tausend Rubel. Diese Daten können in grafischer Form dargestellt werden:


Ausgangsdaten

Einfache exponentielle Glättung
Alpha × (Nachfrage aktuelle Periode – Niveau vorherige Periode)


Vielleicht haben Sie einen Trend

Exponentielle Holt-Glättung mit Trendanpassung



Muster in Daten erkennen


Multiplikative exponentielle Glättung nach Holt-Winters







Erstellen eines Konfidenzintervalls für die Prognose



Ph.D., Direktor für Wissenschaft und Entwicklung von JSC „KIS“
Exponentielle Glättungsmethode
Prognose zu einem Zeitpunkt in der Serie Fi
ein vorgegebener Glättungskoeffizient W, der über die gesamte Serie konstant ist.
Für das 3. Viertel F3 =0,8*6 (1-0,8)*3,8 =5,6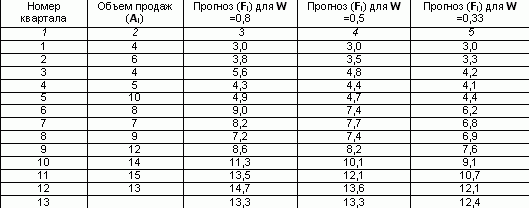
Berechnung der Umsatzprognose

Exponentielle Glättung



