Előrejelzés exponenciális simítási módszer alapján. Példa a probléma megoldására
Hogyan Előrejelzés MOST! jobb modell Exponenciális simítás (ES) az alábbi grafikonon láthatja. Az X tengely a termékszám, az Y tengely az előrejelzés minőségének százalékos javulását jelzi. Olvassa el az alábbiakban a modell leírását, a részletes kutatást és a kísérleti eredményeket.
Modell leírás
Előrejelzési módszer exponenciális simítás az egyik legtöbb egyszerű módokon előrejelzés. Az előrejelzést csak egy időszakra lehet előre beszerezni. Ha az előrejelzés napokban történik, akkor csak egy nappal előre, ha hétre, akkor egy hétre előre.
Összehasonlításképpen, az előrejelzést egy hétre előre 8 hétre végezték el.
Mi az az exponenciális simítás?
Hagyja a sort VEL az eredeti értékesítési sorozatot képviseli az előrejelzéshez
C(1)-értékesítés az első héten, VEL(2) a másodikban és így tovább.

1. ábra Értékesítés heti bontásban, sor VEL
Ugyanígy a sorozat S exponenciálisan simított eladási sorozatot képvisel. Az α együttható nullától egyig terjed. A következőképpen alakul, itt t van egy pillanat az időben (nap, hét)
S (t+1) = S(t) + α *(С(t) - S(t))
Az α simítási állandó nagy értékei felgyorsítják az előrejelzés válaszát a megfigyelt folyamat ugrására, de előre nem látható kiugró értékekhez vezethetnek, mivel szinte nem lesz simítás.
A megfigyelések megkezdése után először, csak egy megfigyelési eredménnyel C (1) , amikor az S (1) nem, és továbbra sem használható az (1) képlet S előrejelzésként (2) C-t kell venni (1) .
A képlet könnyen átírható más formára:
S (t+1) = (1 -α )* S (t)+α * VEL (t).
Így a simítási állandó növekedésével a legutóbbi eladások aránya nő, a simított korábbi eladások aránya pedig csökken.
Az α állandót kísérletileg választjuk ki. Általában több előrejelzés készül a különböző állandókra, és a kiválasztott kritérium szempontjából a legoptimálisabb állandót választják ki.
Kritérium lehet a korábbi időszakokra vonatkozó előrejelzés pontossága.
Vizsgálatunk során olyan exponenciális simítási modelleket vettünk figyelembe, amelyekben α értéket vesz fel (0,2, 0,4, 0,6, 0,8). Összehasonlításképpen a MOST előrejelzéssel! Minden termékhez minden α-ra előrejelzés készült, és a legpontosabb előrejelzést választották ki. A valóságban a helyzet sokkal bonyolultabb lenne, anélkül, hogy előre ismerné az előrejelzés pontosságát, az α együtthatóról, amelytől nagyban függ az előrejelzés minősége. Ez egy ilyen ördögi kör.
Egyértelműen

2. ábra α =0,2, az exponenciális simítás mértéke magas, a valós eladásokat rosszul veszik figyelembe

3. ábra α =0,4, az exponenciális simítás mértéke átlagos, a valós eladásokat átlagos mértékben veszik figyelembe
Látható, hogy a konstans α növekedésével a simított sorozat egyre inkább a valós eladásoknak felel meg, és ha vannak kiugró értékek vagy anomáliák, akkor rendkívül pontatlan előrejelzést kapunk.

4. ábra α =0,6, az exponenciális simítás mértéke alacsony, a valós eladásokat jelentősen figyelembe veszik
Láthatjuk, hogy α=0,8-nál a sorozat szinte pontosan megismétli az eredetit, ami azt jelenti, hogy az előrejelzés a „ugyanannyit adnak el, mint tegnap” szabályhoz hajlik.
Érdemes megjegyezni, hogy itt teljesen lehetetlen az eredeti adatokhoz való közelítés hibájára összpontosítani. Elérheti a tökéletes illeszkedést, de még mindig elfogadhatatlan előrejelzést kaphat.

5. ábra α =0,8, az exponenciális simítás mértéke rendkívül alacsony, a valós eladásokat erősen figyelembe veszik
Példák előrejelzésekre
Most nézzük meg a segítségével kapott előrejelzéseket különböző jelentésekα. Ahogy a 6. és 7. ábrából is látható, minél nagyobb a simítási együttható, annál pontosabban ismétli meg az előrejelzés a valós eladásokat egy lépéses késleltetéssel. Egy ilyen késleltetés valójában kritikus lehet, ezért nem választhatja ki egyszerűen az α maximális értékét. Ellenkező esetben olyan helyzetet kapunk, hogy azt mondjuk, hogy pontosan annyi fogy, mint amennyi az előző időszakban elkelt.

6. ábra Az exponenciális simítási módszer előrejelzése α=0,2-nél

7. ábra Az exponenciális simítási módszer előrejelzése α=0,6-nál
Nézzük meg, mi történik, ha α = 1,0. Emlékezzünk vissza, hogy S előre jelzett (simított) eladás, C pedig valós eladás.
S (t+1) = (1 -α )* S (t)+α * VEL (t).
S (t+1) = VEL (t).
A t+1 napi értékesítés az előrejelzés szerint megegyezik az előző napi értékesítéssel. Ezért az állandó kiválasztását bölcsen kell megközelíteni.
Összehasonlítás az előrejelzéssel MOST!
Most nézzük meg ezt az előrejelzési módszert az Előrejelzés MOST! Az összehasonlítás 256 terméken történt, amelyek értékesítése eltérő, rövid és hosszú távú szezonalitás, „rossz” eladások és hiányok, akciók és egyéb kiugró értékek. Minden termékhez az exponenciális simítási modell segítségével előrejelzést építettünk, a különböző α-k esetében a legjobbat választottuk ki, és a Forecast NOW modellel hasonlítottuk össze az előrejelzéssel.
Az alábbi táblázatban az egyes termékek előrejelzési hibaértékét láthatja. A hibát itt RMSE-nek tekintettük. Ez a gyökere szórás előrejelzés a valóságból. Nagyjából azt mutatja, hogy hány egységnyi áruval tértünk el az előrejelzéstől. A javulás azt mutatja, hogy az Előrejelzés MOST hány százalékkal! Jobb, ha a szám pozitív, és rosszabb, ha negatív. A 8. ábrán az X tengely a termékeket mutatja, az Y tengely pedig azt, hogy mennyi az Előrejelzés MOST! jobb, mint az exponenciális simítással történő előrejelzés. Amint ezen a grafikonon is látható, az előrejelzési pontosság MOST! szinte mindig kétszer olyan magas, és szinte soha nem rosszabb. Ez gyakorlatilag azt jelenti, hogy az Előrejelzés MOST! lehetővé teszi a készletek felére csökkentését vagy a hiány csökkentését.
Egy idősor trendjének azonosítása és elemzése gyakran lapítással vagy simítással történik. Az exponenciális simítás az egyik legegyszerűbb és legelterjedtebb módszer a sorozatok egyengetésére. Az exponenciális simítás szűrőként ábrázolható, melynek bemenetét szekvenciálisan az eredeti sorozat feltételeiből kapjuk, a kimenetet pedig az exponenciális átlag aktuális értékei képezik.
Legyen idősor.
A sorozat exponenciális simítása a következő ismétlődő képlettel történik: , .
Minél kisebb az α, annál jobban kiszűrik és elnyomják az eredeti sorozat ingadozásait és a zajt.
Ha következetesen használjuk ezt az ismétlődő összefüggést, akkor az exponenciális átlag kifejezhető az X idősor értékein keresztül.
Ha a simítás megkezdésekor már léteznek korábbi adatok, akkor az összes rendelkezésre álló adat vagy annak egy részének számtani átlaga használható kiindulási értékként.
R. Brown munkáinak megjelenése után az exponenciális simítást gyakran alkalmazzák az idősorok rövid távú előrejelzésének problémájának megoldására.
A probléma megfogalmazása
Legyen megadva az idősor: .
Meg kell oldani egy idősor előrejelzésének problémáját, azaz. lelet
Előrejelzési horizont, ez szükséges
Az adatok öregedésének figyelembevétele érdekében bevezetünk egy nem növekvő súlysorozatot
Barna modell
Tegyük fel, hogy D kicsi (rövid távú előrejelzés), akkor egy ilyen probléma megoldására használjuk Barna modell.
Ha az előrejelzést egy lépéssel előrébb tekintjük, akkor ennek az előrejelzésnek a hibája, és az új előrejelzés az előző előrejelzés hibájának figyelembe vételével történő kiigazítása eredményeként jön létre - az alkalmazkodás lényege.
A rövid távú előrejelzésben kívánatos az új változások mielőbbi tükrözése, és egyúttal a sorozat lehető legjobb „megtisztítása” a véletlenszerű ingadozásoktól. Hogy. az újabb megfigyelések súlyát növelni kell: .
Másrészt a véletlen eltérések kiegyenlítéséhez α-t csökkenteni kell: .
Hogy. ez a két követelmény ütközik egymással. Az α kompromisszumos értékének megtalálása jelenti a modelloptimalizálási problémát. Az α-t általában a (0,1/3) intervallumból veszik.
Példák

Az α=0,2-es exponenciális simítás munkája a külföldi autómárkák oroszországi eladásairól szóló havi jelentések adatain a 2007. január és 2008. október közötti időszakra vonatkozóan. Figyeljük meg a januári és februári meredek visszaesést, amikor az eladások hagyományosan csökkennek és emelkednek nyár eleje.
Problémák
A modell csak rövid előrejelzési horizonton működik. A trend és a szezonális változásokat nem veszik figyelembe. Befolyásuk figyelembe vételére a következő modellek használata javasolt: Holt (lineáris trendet figyelembe véve), Holt-Winters (multiplikatív exponenciális trend és szezonalitás), Theil-Bér (additív lineáris trend és szezonalitás).
9 5. Exponenciális simítási módszer. Simítási állandó kiválasztása
A módszer alkalmazásakor legkisebb négyzetek az előrejelzési tendencia (trend) meghatározásához előzetesen feltételezzük, hogy minden retrospektív adat (megfigyelés) azonos információtartalommal rendelkezik. Nyilvánvalóan logikusabb lenne figyelembe venni a kezdeti információk diszkontálásának folyamatát, vagyis ezen adatok egyenlőtlenségét az előrejelzés kialakításához. Ezt az exponenciális simítási módszerrel úgy érik el, hogy az idősorok legfrissebb megfigyelései (azaz az előrejelzési átfutási időszakot közvetlenül megelőző értékek) jelentősebb „súlyokat” adnak a kezdeti megfigyelésekhez képest. Az exponenciális simítási módszer előnyei közé tartozik a számítási műveletek egyszerűsége és a különböző folyamatdinamikák leírásának rugalmassága is. A módszer a középtávú előrejelzések megvalósításában találta a legnagyobb alkalmazást.
5.1. Az exponenciális simítási módszer lényege
A módszer lényege, hogy az idősort egy súlyozott „mozgóátlag” segítségével simítjuk, amelyben a súlyok engedelmeskednek az exponenciális törvénynek. Más szóval, minél távolabb van az idősor végétől az a pont, amelyre a súlyozott mozgóátlagot számítják, annál kevesebb „részvétel kell” az előrejelzés kialakításában.
Legyen az eredeti dinamikus sorozat y t , t = 1 , 2 ,...,n szintekből (sorkomponensekből) álljon. A sorozat minden m egymást követő szintjére
(m dinamikus sorozat egy lépéssel. Ha m páratlan szám, és célszerű páratlan számú szintet venni, mivel ebben az esetben a számított szintérték a simítási intervallum közepén lesz, és könnyen helyettesítheti a tényleges értéket, akkor a következő képlet a mozgóátlag meghatározásához írjuk: t+ ξ t+ ξ ∑ yi ∑ yi i= t− ξ i= t− ξ 2ξ + 1 ahol y t a t pillanat mozgóátlaga (t = 1, 2,...,n y i a szint aktuális értéke az i pillanatban); i – a szint sorszáma a simítási intervallumban. A ξ értékét a simítási intervallum időtartamából határozzuk meg. Mert m =2 ξ +1 akkor páratlan m-re ξ = m 2 − 1. A nagy számú szinttel rendelkező mozgóátlag kiszámítása leegyszerűsíthető az egymást követő mozgóátlag értékek rekurzív meghatározásával: y t= y t− 1 + yt + ξ − y t − (ξ + 1 ) 2ξ + 1 De abból a tényből kiindulva, hogy nagyobb „súlyt” kell tulajdonítani a legutóbbi megfigyeléseknek, a mozgóátlag más értelmezést igényel. Ez abban rejlik, hogy az átlagolással kapott érték nem az átlagolási intervallum középső tagját, hanem az utolsó tagját helyettesíti. Ennek megfelelően az utolsó kifejezés átírható a formába Mi = Mi + 1 y i− y i− m Itt az intervallum végére utaló mozgóátlagot az új M i szimbólum jelzi. Lényegében M i egyenlő y t ξ lépéssel jobbra tolva, vagyis M i = y t + ξ, ahol i = t + ξ. Figyelembe véve, hogy M i − 1 az y i − m mennyiség becslése, az (5.1) kifejezés formában átírható y i+1 M i − 1 , M i , amelyet az (5.1) kifejezés határozza meg. ahol M i a becslés Ha az (5.2) számításokat megismételjük, amikor új információ érkezik és átírjuk más formában, simított megfigyelési függvényt kapunk: Q i= α y i+ (1 − α ) Q i − 1 , vagy azzal egyenértékű formában Q t= α y t+ (1 − α ) Q t− 1 Az (5.3) kifejezéssel minden új megfigyeléssel végzett számításokat exponenciális simításnak nevezzük. Az utolsó kifejezésben az exponenciális simítás és a mozgóátlag megkülönböztetésére a Q jelölést vezetjük be M helyett. Az α mennyiség, amely az m 1 analógját simítási állandónak nevezzük. Az α értékei benne vannak intervallum [0, 1]. Ha α-t sorozatként ábrázoljuk α + α(1 - α) + α(1 - α) 2 + α(1 - α) 3 + ... + α(1 - α) n , akkor könnyen észrevehető, hogy a „súlyok” időben exponenciálisan csökkennek. Például α = 0 esetén 2 kapjuk 0,2 + 0,16 + 0,128 + 0,102 + 0,082 + … A sorozatok összege egységre törekszik, és az összeg tagjai idővel csökkennek. Q t értéke az (5.3) kifejezésben az elsőrendű exponenciális átlag, vagyis a közvetlenül a simító megfigyelési adatok (elsődleges simítás). A statisztikai modellek kidolgozásakor néha célszerű magasabb rendű exponenciális átlagok, azaz ismételt exponenciális simítással kapott átlagok számításához folyamodni. Az általános jelölés ismétlődő formában a k exponenciális átlagrendhez: Q t (k)= α Q t (k− 1 )+ (1 − α ) Q t (− k1 ). A k értéke 1, 2, ..., p,p+1 között változik, ahol p az előrejelzési polinom sorrendje (lineáris, másodfokú stb.). Az első, második és harmadrendű exponenciális átlagra vonatkozó képlet alapján a kifejezéseket kapjuk Q t (1 )= α y t + (1 − α ) Q t (− 1 1 ); Q t (2 )= α Q t (1 )+ (1 − α ) Q t (− 2 1 ); Q t (3 )= α Q t (2 )+ (1 − α ) Q t (− 3 1 ). 5.2. Az előrejelzési modell paramétereinek meghatározása exponenciális simítási módszerrel Nyilvánvaló, hogy az exponenciális simítási módszerrel idősoron alapuló előrejelzési értékek kidolgozásához exponenciális átlagokkal kell kiszámítani a trendegyenlet együtthatóit. Az együtthatóbecsléseket az alapvető Brown-Meyer-tétel segítségével határozzuk meg, amely a prediktív polinom együtthatóit a megfelelő sorrendek exponenciális átlagaival köti össze: (−
1
) aˆ p α (1 − α )∞ −α
)
j (p − 1 + j ) ! ∑j p = 0 p! (k− 1 ) !j = 0 ahol aˆ p a fokpolinom együtthatóinak becslései. Az együtthatókat a сp + 1 (p + 1) egyenletrendszer megoldásával találjuk meg ismeretlen. Tehát a lineáris modellhez aˆ 0 = 2 Q t (1 ) − Q t (2 ) ; aˆ 1 = 1 − α α (Q t (1 )− Q t (2 )) ; másodfokú modellhez aˆ 0 = 3 (Q t (1 )− Q t (2 )) + Q t (3 ); aˆ 1 =1 − α α [ (6 −5 α ) Q t (1 ) −2 (5 −4 α ) Q t (2 ) +(4 −3 α ) Q t (3 ) ] ; aˆ 2 = (1 − α α ) 2 [ Q t (1 )− 2 Q t (2 )+ Q t (3 )]. Az előrejelzés a kiválasztott polinom segítségével valósul meg a lineáris modellhez ˆyt + τ = aˆ0 + aˆ1 τ ; másodfokú modellhez ˆyt + τ = aˆ0 + aˆ1 τ + aˆ 2 2 τ 2, ahol τ az előrejelzési lépés. Megjegyzendő, hogy a Q t (k) exponenciális átlagok csak ismert (kiválasztott) paraméterrel számíthatók, a Q 0 (k) kezdeti feltételek ismeretében. A kezdeti feltételek becslése, különösen egy lineáris modell esetében Q(1)=a 1 − α Q(2 ) = a− 2 (1 − α ) a másodfokú modellhez Q(1)=a 1 − α + (1 − α )(2 − α ) a 2(1− α ) (1−α)(3−2α) Q 0(2 ) = a 0− 2α 2 Q(3)=a 3(1− α ) (1 − α )(4 − 3 α ) a ahol az a 0 és a 1 együtthatókat a legkisebb négyzetek módszerével számítjuk ki. Az α simítási paraméter értékét hozzávetőlegesen a képlet számítja ki α ≈ m 2 + 1, ahol m a megfigyelések (értékek) száma a simítási intervallumban. Az előrejelzési értékek kiszámításának sorrendje a következő helyen található: Soros együtthatók számítása a legkisebb négyzetek módszerével A simítási intervallum meghatározása A simítási állandó számítása Kiindulási feltételek számítása Exponenciális átlagok számítása Becslések számítása a 0 , a 1 stb. Sorozat előrejelzett értékeinek kiszámítása Rizs. 5.1. Az előrejelzett értékek számítási sorrendje Példaként tekintsük a termék meghibásodásmentes működésének előrejelzett értékét, amelyet a meghibásodások közötti átlagos idővel fejezünk ki. A kezdeti adatokat táblázatban foglaltuk össze. 5.1. Lineáris előrejelzési modellt választunk y t = a 0 + a 1 τ formában A megoldás a kezdeti mennyiségek következő értékeivel megvalósítható: a 0, 0 = 64, 2; a 1, 0 = 31, 5; α = 0,305. 5.1. táblázat. Kezdeti adatok Megfigyelési szám, t Lépéshossz, előrejelzés, τ MTBF, y (óra) Ezekkel az értékekkel a számított „kisimított” együtthatók y 2 értéke egyenlő lesz = α Q (1) − Q (2) = 97, 9; [ Q (1 )− Q (2 ) 31,
9 , 1− α kezdeti feltételek mellett 1 − α A 0 , 0 − egy 1, 0 = −7
,
6
1 − α = −79
,
4
és exponenciális átlagok Q (1 )= α y + (1 − α ) Q (1 ) 25,
2;
Q(2) = α Q (1) + (1 −α ) Q (2 ) = −47 . Az y 2 „simított” értéket a képlet segítségével számítjuk ki Qi (1) Qi (2) a 0,i egy 1,i ˆyt Így (5.2. táblázat) a lineáris előrejelzési modell formája van ˆy t + τ = 224,5+ 32τ . Számítsuk ki a 2 év (τ = 1), 4 év (τ = 2) és így tovább a termékmeghibásodások közötti átfutási időkre vonatkozó előrejelzett értékeket (5.3. táblázat). 5.3. táblázat. Előrejelzési értékekˆy t Egyenlet t+2 t+4 t+6 t+8 t+20 regresszió (τ = 1) (τ = 2) (τ = 3) (τ = 5) τ =
ˆy t = 224,5+ 32τ Meg kell jegyezni, hogy az idősor utolsó m értékének teljes „súlyát” a képlet segítségével lehet kiszámítani c = 1 − (m (− 1 ) m ) . m+1 Tehát a sorozat utolsó két megfigyelésére (m = 2) a c = 1 − (2 2 − + 1 1) 2 = 0,667 érték. 5.3. A kezdeti feltételek kiválasztása és a simítási állandó meghatározása Ahogy a kifejezésből következik Q t= α y t+ (1 − α ) Q t − 1 , Az exponenciális simítás végrehajtásakor ismerni kell a simított függvény kezdeti (korábbi) értékét. Egyes esetekben az első megfigyelést gyakrabban vehetjük kezdeti értéknek, a kezdeti feltételeket az (5.4) és (5.5) kifejezések szerint határozzuk meg. Ebben az esetben az értékek a 0, 0, a 1, 0 és a 2 , 0 a legkisebb négyzetek módszerével van meghatározva. Ha nem nagyon bízunk a választott kezdeti értékben, akkor az α simítási állandó nagy értékét k megfigyelésen keresztül kapjuk a kezdeti érték „súlya” az (1 − α ) k értékre<<
α
, и оно будет практически забыто. Наоборот, если мы уверены в правильности выбранного начального значения и неизменности модели в течение определенного отрезка времени в будущем,α
может быть выбрано малым (близким к 0). Így a simítási állandó (vagy a megfigyelések száma mozgóátlagban) kiválasztása kompromisszumos döntés meghozatalával jár. Amint a gyakorlat azt mutatja, a simítási állandó értéke általában 0,01 és 0,3 közötti tartományban van. Számos olyan átmenet ismert, amelyek lehetővé teszik az α közelítő becslését. Az első a mozgó és az exponenciális átlag egyenlőségének feltételéből következik α = m 2 + 1, ahol m a megfigyelések száma a simítási intervallumban. Más megközelítések az előrejelzés pontosságához kapcsolódnak. Így a Meyer-reláció alapján meg lehet határozni α-t: α ≈ S y, ahol S y – a modell négyzetes középhibája; S 1 – az eredeti sorozat négyzetes középhibája. Ez utóbbi összefüggés használatát azonban nehezíti, hogy nagyon nehéz megbízhatóan meghatározni S y-t és S 1-et a kezdeti információkból. Gyakran a simítási paraméter, és egyben az együtthatók a 0, 0 és a 0, 1 a kritériumtól függően optimálisak S 2 = α ∑ ∞ (1 − α ) j [ yij − ˆyij ] 2 → min j = 0 egy algebrai egyenletrendszer megoldásával, amelyet a derivált nullával való egyenlővé tételével kapunk ∂S2 ∂S2 ∂S2 ∂a 0, 0 ∂a 1, 0 ∂a 2, 0 Így egy lineáris előrejelzési modellnél a kezdeti kritérium egyenlő S 2 = α ∑ ∞ (1 − α ) j [ yij − a0, 0 − a1, 0 τ] 2 → min. j = 0 Ennek a rendszernek a számítógépes megoldása nem jelent nehézséget. Az α ésszerű kiválasztásához használhatja az általánosított simítási eljárást is, amely lehetővé teszi a következő összefüggések elérését az előrejelzési variancia és a lineáris modell simítási paramétere között: S p 2 ≈[ 1 + α β ] 2 [ 1 +4 β +5 β 2 +2 α (1 +3 β ) τ +2 α 2 τ 3 ] S y 2 másodfokú modellhez S p 2≈ [ 2 α + 3 α 3 + 3 α 2τ ] S y 2, ahol β =
1
−
α
;Sy– Az eredeti idősor közelítésének RMS eltérése. Az előrejelzési problémák bizonyos adatok időbeli változásán (értékesítés, kereslet, készletek, GDP, szén-dioxid-kibocsátás, népesség...) és ezen változások jövőre vetítésén alapulnak. Sajnos a történelmi adatokból azonosított tendenciákat számos előre nem látható körülmény megzavarhatja. Így a jövőbeni adatok jelentősen eltérhetnek a múltban történtektől. Ez az előrejelzés problémája. Vannak azonban olyan technikák (úgynevezett exponenciális simítás), amelyek lehetővé teszik, hogy ne csak a jövőt próbálják megjósolni, hanem számszerűsítsék az előrejelzéshez kapcsolódó minden bizonytalanságát is. A bizonytalanság numerikus kifejezése előrejelzési intervallumok létrehozásával valóban felbecsülhetetlen, de az előrejelzések világában gyakran figyelmen kívül hagyják. Töltse le a jegyzetet vagy formátumban, a példákat formátumban Tegyük fel, hogy Ön a „Gyűrűk Ura” rajongója, és már három éve készít és árul kardokat (1. ábra). Jelentsük meg grafikusan az eladásokat (2. ábra). Három év alatt megduplázódott a kereslet – talán ez a tendencia? Erre a gondolatra kicsit később visszatérünk. A grafikonon több csúcs és völgy is található, ami a szezonalitás jele lehet. Pontosabban, a csúcsok a 12., 24. és 36. hónapban következnek be, ami történetesen december. De lehet, hogy ez csak véletlen? Találjuk ki. Az exponenciális simítási módszerek a jövő előrejelzésére támaszkodnak a múltból származó adatokból, ahol az újabb megfigyelések nagyobb súllyal bírnak, mint a régebbiek. Ez a súlyozás a simítási állandóknak köszönhetően lehetséges. Az első exponenciális simítási módszert egyszerű exponenciális simításnak (SES) nevezzük. Csak egy simítási állandót használ. Az egyszerű exponenciális simítás azt feltételezi, hogy az idősor adatai két összetevőből állnak: egy szintből (vagy átlagból) és az érték körüli hibából. Nincs trend vagy szezonális ingadozás - egyszerűen van egy szint, amely körül ingadozik a kereslet, itt-ott apró hibákkal körülvéve. Az újabb megfigyelések előnyben részesítésével a TEC ezen a szinten eltolódásokat okozhat. A képletek nyelvén, Kereslet t időpontban = szint + véletlenszerű hiba a szint körül a t időpontban Tehát hogyan találja meg a hozzávetőleges szintértéket? Ha minden időértéket azonos értékűnek fogadunk el, akkor egyszerűen ki kell számítanunk az átlagértéküket. Ez azonban egy rossz ötlet. Nagyobb súlyt kell tulajdonítani a közelmúltbeli megfigyeléseknek. Hozzunk létre több szintet. Számítsuk ki a kezdeti szintet az első évben: 0. szint = átlagos kereslet az első évben (1-12. hónap) A kardok kereslete 163. Az 1. hónapra előrejelzett keresletként a 0 (163) szintet használjuk. Az 1. hónapra vonatkozó kereslet 165, azaz 2 karddal 0 szint felett van. Érdemes frissíteni az alapközelítést. Az egyszerű exponenciális simítás egyenlete: 1. szint = 0. szint + néhány százalék × (1. igény – 0. szint) 2. szint = 1. szint + néhány százalék × (2. igény – 1. szint) Stb. A „néhány százalékot” simítási állandónak nevezzük, és alfa-val jelöljük. Ez tetszőleges szám lehet 0 és 100% között (0 és 1 között). Később megtanulja, hogyan kell kiválasztani az alfa értéket. Általában a különböző időpontok értékei: Szint aktuális időszak = szint előző időszak + A jövőbeli kereslet megegyezik az utoljára számított szinttel (3. ábra). Mivel nem tudja, mi az alfa, állítsa a C2 cellát 0,5-re. A modell felépítése után keressen egy olyan alfát, amelynél a hibanégyzet - E2 (vagy szórás - F2) összege minimális. Ehhez futtassa az opciót Megoldás keresése. Ehhez menjen végig a menün ADAT –> Megoldás keresése, és telepítse az ablakba Megoldáskeresési beállítások szükséges értékeket (4. ábra). Az előrejelzési eredmények diagramon való megjelenítéséhez először válassza ki az A6:B41 tartományt, és készítsen egy egyszerű vonaldiagramot. Ezután kattintson a jobb gombbal a diagramra, és válassza ki a lehetőséget Válassza ki az adatokat. A megnyíló ablakban hozzon létre egy második sort, és szúrjon be előrejelzéseket az A42:B53 tartományból (5. ábra). Ennek a feltevésnek a teszteléséhez elegendő egy lineáris regressziót illeszteni a keresleti adatokra, és elvégezni egy t tesztet ennek a trendvonalnak az emelkedésén (ahogyan). Ha az egyenes meredeksége nem nulla és statisztikailag szignifikáns (a Student-féle t-próbával végzett tesztelésnél az érték r kisebb, mint 0,05), az adatoknak van trendje (6. ábra). Használtuk a LINEST függvényt, amely 10 leíró statisztikát ad vissza (ha még nem használta ezt a funkciót, akkor ezt javaslom) és az INDEX függvényt, amivel csak a három szükséges statisztikát lehet „kihúzni”, nem a teljes készletet. Kiderült, hogy a meredekség 2,54, és ez szignifikáns, mivel a Student-féle teszt azt mutatta, hogy a 0,000000012 szignifikánsan kisebb, mint 0,05. Tehát van egy tendencia, és már csak azt kell belefoglalni az előrejelzésbe. Gyakran dupla exponenciális simításnak nevezik, mert nem egy simítási paramétere van - alfa, hanem kettő. Ha egy idősorozatnak lineáris trendje van, akkor: t idő igény = szint + t × trend + véletlenszerű szinteltérés a t időpontban A Holt Exponenciális Simítás Trend Adjustment funkcióval két új egyenlettel rendelkezik, az egyik az időben haladó szintre, a másik pedig a trendre. A szintegyenlet egy alfa simítási paramétert, a trendegyenlet pedig a gammát tartalmazza. Így néz ki az új szintegyenlet: 1. szint = 0. szint + 0. trend + alfa × (1. igény – (0. szint + 0. trend)) jegyezze meg 0. szint + trend 0 csak egy lépéses előrejelzés a kezdeti értékektől az 1. hónapig, tehát kereslet 1 – (0. szint + 0. trend)- ez egy lépéses eltérés. Így az alapszintű közelítési egyenlet a következő lesz: szint aktuális időszak = előző időszak szint + előző időszak trend + alfa × (kereslet aktuális időszak – (előző időszak szint) + előző időszak trendje) Trendfrissítési egyenlet: trend aktuális időszak = trend előző időszak + gamma × alfa × (keresleti aktuális időszak – (előző időszak szintje) + előző időszak trendje) A Holt-simítás az Excelben hasonló az egyszerű simításhoz (7. ábra), és ahogy fentebb is, a cél az, hogy két együtthatót találjunk, miközben minimalizáljuk a négyzetes hibák összegét (8. ábra). A kezdeti szint és trendértékek (a 7. ábra C5 és D5 cellájában) megszerzéséhez készítsen egy grafikont az értékesítés első 18 hónapjáról, és adjon hozzá egy trendvonalat egyenlettel. Adja meg a 0,8369 kezdeti trendértéket és a 155,88 kezdeti szintet a C5 és D5 cellákban. Az előrejelzési adatok grafikusan is megjeleníthetők (9. ábra). Rizs. 7. Holt exponenciális simítás trend beállítással; A kép nagyításához kattintson rá jobb gombbal, és válassza ki Kép megnyitása új lapon Van mód a prediktív modell erősségének tesztelésére – hasonlítsa össze a hibákat önmagukkal, egy lépéssel (vagy több lépéssel) eltolva. Ha az eltérések véletlenszerűek, akkor a modell nem javítható. A keresleti adatokban azonban lehet szezonális tényező. A hibatag fogalmát, amely korrelál egy másik periódus verziójával, autokorrelációnak nevezzük (az autokorrelációról bővebben lásd: ). Az autokorreláció kiszámításához kezdje az egyes időszakokra vonatkozó előrejelzési hibaadatokkal (a 7. ábra F oszlopa a 10. ábra B oszlopába kerül). Ezután határozza meg az átlagos előrejelzési hibát (10. ábra, B39 cella; képlet a cellában: =AVERAGE(B3:B38)). A C oszlopban számítsa ki az előrejelzési hiba átlagtól való eltérését; képlet a C3 cellában: =B3-B$39. Ezután egymás után tolja el a C oszlopot egy oszloppal jobbra és egy sorral lefelé. Képletek a D39 cellákban: =ÖSSZEG($C3:$C38,D3:D38), D41: =D39/$C39, D42: =2/SQRT(36), D43: =-2/SQRT(36). Mit jelent az, hogy az egyik D:O oszlop „szinkron” a C oszloppal Például, ha a C és a D oszlopok szinkronok, akkor az egyikben negatív számnak negatívnak, pozitívnak kell lennie a másikban? egyben pozitív barátban. Ez azt jelenti, hogy a két oszlop szorzatának összege szignifikáns lesz (a különbségek halmozódnak). Vagy ami ugyanaz, minél közelebb van a D41:O41 tartományban lévő érték nullához, annál kisebb a korrelációja az oszlopnak (D-től O-ig) a C oszlophoz (11. ábra). Egy autokorreláció a kritikus érték felett van. Az egy évvel eltolt hiba önmagával korrelál. Ez 12 hónapos szezonális ciklust jelent. És ez nem meglepő. Ha megnézzük a keresleti grafikont (2. ábra), kiderül, hogy minden karácsonykor csúcsok a kereslet, április-májusban pedig mélypontok vannak. Vegyünk egy olyan előrejelzési technikát, amely figyelembe veszi a szezonalitást. A módszert multiplikatívnak nevezik (a szorzásból - szorzás), mert a szorzást használja a szezonalitás figyelembevételére: Kereslet a t időpontban = (szint + t × trend) × szezonális kiigazítás a t időpontban × minden fennmaradó szabálytalan kiigazítás, amelyet nem tudunk figyelembe venni A Holt-Winters simítást háromszoros exponenciális simításnak is nevezik, mert három simítási paramétere van (alfa, gamma és delta). Például, ha van egy 12 hónapos szezonális ciklus: Előrejelzés a 39. hónapra = (36. szint + 3 × trend 36) x szezonalitás 27 Az adatok elemzésekor ki kell deríteni, hogy egy adatsorban mi a trend, és mi a szezonalitás. A Holt-Winters módszerrel végzett számításokhoz a következőket kell tennie: Kezdje a nyers adatokkal (A és B oszlop a 12. ábrán), és adja hozzá a C oszlopot a mozgóátlag simított értékeivel. Mivel a szezonalitásnak 12 hónapos ciklusai vannak, célszerű 12 hónapos átlagot használni. Ezzel az átlaggal van egy kis probléma. A 12 páros szám. Ha kisimítja a 7. havi keresletet, akkor azt az 1. és 12. hónap közötti átlagos keresletnek tekintse, vagy a 2. és 13. hónap közötti átlagos keresletnek? Ennek a nehézségnek a leküzdéséhez ki kell simítania a keresletet a „2x12 mozgóátlag” segítségével. Vagyis vegyük a két átlag felét 1-től 12-ig és 2-től 13-ig. A képlet a C8 cellában: =(ÁTLAG(B3:B14)+ÁTLAG(B2:B13))/2. Az 1–6. és a 31–36. hónapra vonatkozó simított adatok nem szerezhetők be, mivel nincs elegendő korábbi és következő időszak. Az áttekinthetőség kedvéért az eredeti és a simított adatok tükrözhetők a diagramon (13. ábra). Most a D oszlopban ossza el az eredeti értéket a simított értékkel, és kapja meg a hozzávetőleges szezonális korrekciós értéket (12. ábra D oszlopa). A D8 cellában lévő képlet =B8/C8. Vegye figyelembe a 12. és 24. (december) hónapban a normál kereslet feletti 20%-os kiugrásokat, míg tavasszal mélypontok figyelhetők meg. Ez a simítási technika minden hónapra két pontbecslést adott (összesen 24 hónap). Az E oszlop e két tényező átlagát keresi. Képlet az E1 cellában: =ÁTLAG(D14,D26). Az érthetőség kedvéért a szezonális ingadozás mértékét grafikusan is bemutathatjuk (14. ábra). A szezonálisan kiigazított adatok már elérhetők. A G1 cellában a képlet a következő: =B2/E2. Készítsen grafikont a G oszlop adatai alapján, egészítse ki egy trendvonallal, jelenítse meg a trendegyenletet a diagramon (15. ábra), és használja fel az együtthatókat a későbbi számításoknál. A képen látható módon alakítsunk ki egy új lapot. 16. Helyettesítse az értékeket az E5:E16 tartományban a 2. ábráról. 12 terület E2:E13. Vegyük a C16 és D16 értékeket az ábra trendvonal-egyenletéből. 15. Állítsa a simítási állandók értékeit 0,5-re. Húzza ki a 17. sorban lévő értékeket, hogy lefedje az 1. és 36. hónap közötti tartományt. Futtassa Megoldás keresése a simítási együtthatók optimalizálására (18. ábra). A B53 cellában lévő képlet a következő: =(C$52+(A53-A$52)*D$52)*E41. Most ellenőriznie kell az autokorrelációkat az előrejelzésben (18. ábra). Mivel az összes érték a felső és az alsó határ között helyezkedik el, megérti, hogy a modell jó munkát végzett a keresleti értékek szerkezetének megértésében. Tehát van egy teljesen működő előrejelzésünk. Hogyan állíthat be felső és alsó határokat, amelyek alapján reális feltételezéseket lehet tenni? Ebben segít a Monte Carlo szimuláció, amellyel már találkozott (lásd még). Az ötlet az, hogy jövőbeli forgatókönyveket készítsenek a keresleti viselkedésről, és azonosítsák azt a csoportot, amelybe ezek 95%-a tartozik. Távolítsa el az előrejelzést az Excel munkalap B53:B64 celláiból (lásd: 17. ábra). Ott rögzíted a keresletet a szimuláció alapján. Ez utóbbi a NORMINV függvény segítségével generálható. A következő hónapokra csak az átlagot (0), a standard eloszlást (10,37 a $H$2 cellából) és egy 0 és 1 közötti véletlen számot kell megadnia. A függvény harangnak megfelelő valószínűséggel adja vissza az eltérést. görbe. Helyezze az egylépéses hibaszimulációt a G53 cellába: =NORMIN(RAND(),0,H$2). Feszítse le ezt a képletet G64-re, és előrejelzési hibaszimulációkat kap egy egylépéses előrejelzés 12 hónapjára (19. ábra). A szimulációs értékei eltérnek az ábrán láthatóktól (ezért szimuláció!). Az előrejelzési bizonytalanság révén mindennel megvan, ami a szint, a trend és a szezonális együttható frissítéséhez szükséges. Tehát jelölje ki a C52:F52 cellákat, és nyújtsa ki őket a 64. sorig. Ennek eredményeként egy szimulált előrejelzési hiba és maga az előrejelzés is van. Ennek ellenkezője alapján megjósolhatjuk a keresleti értékeket. Illessze be a képletet a B53: =F53+G53 cellába, és nyújtsa B64-re (20. ábra, B53:F64 tartomány). Most megnyomhatja az F9 gombot, és minden alkalommal frissítheti az előrejelzést. Helyezze el az 1000 szimuláció eredményét az A71:L1070 cellákba, minden alkalommal transzponálva a B53:B64 tartományból az A71:L71, A72:L72, ... A1070:L1070 tartományba. Ha ez zavar, írj valami VBA kódot. Mostantól minden hónapra 1000 forgatókönyv áll rendelkezésére, és a PERCENTILE függvény segítségével megkaphatja a felső és alsó határt a 95%-os konfidencia intervallum közepén. Az A66 cellában a képlet a következő: =PERCENTIL(A71:A1070,0,975), az A67 cellában pedig: =PERCENTIL(A71:A1070,0,025). Szokás szerint az áttekinthetőség kedvéért az adatok grafikusan is megjeleníthetők (21. ábra). Két érdekes pont van a grafikonon: John Foreman könyve alapján íródott. – M.: Alpina Kiadó, 2016. – P. 329–381 Az új fejlesztések és az ismert irányítási technológiák elemzése, amelyek javíthatják az üzletvezetés hatékonyságát, különösen aktuálissá válik az orosz vállalatok számára. Az egyik legnépszerűbb eszköz a költségvetési rendszer, amely a vállalati költségvetés kialakításán és a végrehajtás utólagos nyomon követésén alapul. A költségvetés kiegyensúlyozott rövid távú kereskedelmi, termelési, pénzügyi és gazdasági terveket jelent a szervezet fejlesztésére. A vállalati költségvetés olyan célokat tartalmaz, amelyeket előrejelzési adatok alapján számítanak ki. Bármely vállalkozás költségvetésének elkészítésekor a legjelentősebb előrejelzés az értékesítési előrejelzés. A korábbi cikkekben az additív és multiplikatív modell elemzését végeztük el, és kiszámítottuk a következő időszakokra várható értékesítési volument. Az idősorok elemzésénél a mozgóátlagos módszert alkalmaztuk, amelyben minden adat, függetlenül az előfordulás időszakától, egyenlő. Van egy másik módja az adatok súlyozásának: a frissebb adatok nagyobb súlyt kapnak, mint a korábbi adatok. Az exponenciális simítási módszer a mozgóátlag módszertől eltérően a jövőbeli trendek rövid távú előrejelzésére is használható egy időszakra előre, és automatikusan korrigálja az előrejelzéseket a tényleges és az előrejelzett eredmények közötti különbségek függvényében. Éppen ezért a módszernek egyértelmű előnye van a korábban tárgyalthoz képest. A módszer elnevezése onnan ered, hogy a teljes idősoron exponenciálisan súlyozott mozgóátlagokat állít elő. Az exponenciális simításnál minden korábbi megfigyelést figyelembe veszünk - az előzőt maximális súllyal, az azt megelőzőt valamivel kisebb súllyal, a legkorábbi megfigyelés minimális statisztikai súllyal befolyásolja az eredményt. Az exponenciálisan simított értékek kiszámításának algoritmusa az i sorozat bármely pontján három mennyiségen alapul: Ai tényleges értéke az i sorozat egy adott pontjában, Az új előrejelzés a következőképpen írható fel: Exponenciálisan simított értékek számítása
Az exponenciális simítási módszer gyakorlati alkalmazása során két probléma merül fel: az eredményeket jelentősen befolyásoló simítási együttható (W) megválasztása és a kezdeti feltétel (Fi) meghatározása. Egyrészt a véletlenszerű eltérések kiegyenlítéséhez csökkenteni kell az értéket. Másrészt az új méretek súlyának növeléséhez növelni kell. Bár elvileg W bármilyen értéket vehet fel a 0 tartományból< W < 1, обычно ограничиваются интервалом от 0,2 до 0,5. При высоких значениях коэффициента сглаживания в большей степени учитываются мгновенные текущие наблюдения отклика (для динамично развивающихся фирм) и, наоборот, при низких его значениях сглаженная величина определяется в большей степени прошлой тенденцией развития, нежели текущим состоянием отклика системы (в условиях стабильного развития рынка). A simítási állandó megválasztása szubjektív. A legtöbb vállalat elemzői a hagyományos W-értékeket használják a sorozatok feldolgozásakor, így a Kodak analitikai osztályán közzétett adatok szerint hagyományosan 0,38, a Ford Motorsnál pedig 0,28 vagy 0,3 értéket használnak. Az exponenciális simítás kézi számítása rendkívül nagy mennyiségű monoton munkát igényel. A példa segítségével az egyszerű exponenciális simítási módszerrel kiszámítjuk a 13. negyedévre vonatkozó előrejelzési mennyiséget, ha az utolsó 12 negyedévre rendelkezésre állnak értékesítési adatok. Tegyük fel, hogy az első negyedéves eladási előrejelzés 3 volt. És legyen a W simítási együttható 0,8. Töltsük ki a táblázat harmadik oszlopát úgy, hogy minden következő negyedévben helyettesítsük az előző értékét a következő képlet segítségével: A 2. negyedévre F2 =0,8*4 (1-0,8)*3 =3,8 Hasonlóképpen a simított értéket a 0,5 és 0,33 együtthatóra számítjuk. A W = 0,8-as értékesítési volumen előrejelzése a 13. negyedévben 13,3 ezer rubelt tett ki. Ezek az adatok grafikus formában is bemutathatók:


Kezdeti adatok

Egyszerű exponenciális simítás
alfa × (folyamatbeli kereslet – előző időszak szintje)


Talán van egy trended

Holt exponenciális simítás trendbeállítással



Minták azonosítása az adatokban


Holt-Winters multiplikatív exponenciális simítás







Konfidenciaintervallum felépítése az előrejelzéshez



Ph.D., a JSC "KIS" tudományos és fejlesztési igazgatója
Exponenciális simítási módszer
előrejelzés a Fi sorozat egy pontján
valamilyen előre meghatározott W simítási együttható, állandó a teljes sorozatban.
A 3. negyedévre F3 =0,8*6 (1-0,8)*3,8 =5,6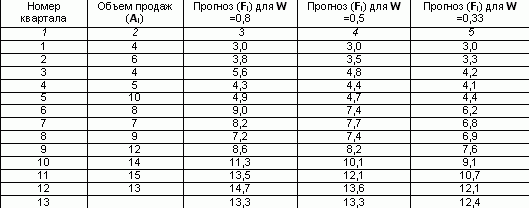
Az értékesítési volumen előrejelzésének kiszámítása

Exponenciális simítás



