Prognoza bazata pe metoda de netezire exponentiala. Exemplu de rezolvare a problemei
În ceea ce privește Prognoza ACUM! model mai bun Netezire exponențială (ES) puteți vedea în graficul de mai jos. Pe axa X - numărul articolului, pe axa Y - îmbunătățirea procentuală a calității prognozei. Descrierea modelului, studiu detaliat, rezultatele experimentelor, citiți mai jos.
Descrierea modelului
Metoda de prognoză netezire exponenţială este unul dintre cei mai moduri simple prognoza. O prognoză poate fi obținută doar pentru o perioadă înainte. Dacă prognoza se realizează în termeni de zile, atunci doar o zi înainte, dacă săptămâni, atunci o săptămână.
Pentru comparație, prognoza a fost efectuată cu o săptămână înainte, timp de 8 săptămâni.
Ce este netezirea exponențială?
Lasă rândul CU reprezintă seria originală de vânzări pentru prognoză
C(1)- vânzări în prima săptămână CU(2) în al doilea și așa mai departe.

Figura 1. Vânzări pe săptămână, serii CU
La fel, un rând S reprezintă o serie de vânzări netezită exponențial. Coeficientul α este de la zero la unu. Rezultă după cum urmează, aici t este un moment în timp (zi, săptămână)
S (t+1) = S(t) + α *(С(t) - S(t))
Valorile mari ale constantei de netezire α accelerează răspunsul prognozei la saltul în procesul observat, dar pot duce la valori aberante imprevizibile, deoarece netezirea va fi aproape absentă.
Pentru prima dată după începerea observațiilor, având un singur rezultat al observațiilor C (1) când prognoza S (1) nu, și este încă imposibil să se utilizeze formula (1), ca prognoză S (2) ar trebui să ia C (1) .
Formula poate fi rescrisă cu ușurință într-o formă diferită:
S (t+1) = (1 -α )* S (t) +α * CU (t).
Astfel, cu o creștere a constantei de netezire, ponderea vânzărilor recente crește, iar ponderea vânzărilor anterioare netezite scade.
Constanta α este aleasă empiric. De obicei, se fac mai multe prognoze pentru diferite constante și cea mai optimă constantă este selectată în funcție de criteriul selectat.
Criteriul poate fi acuratețea prognozei pentru perioadele anterioare.
În studiul nostru, am luat în considerare modele de netezire exponențială în care α ia valorile (0,2, 0,4, 0,6, 0,8). Pentru comparație cu Prognoza ACUM! pentru fiecare produs s-au făcut prognoze pentru fiecare α și s-a ales cea mai precisă prognoză. În realitate, situația ar fi mult mai complicată, utilizatorul, neștiind în prealabil acuratețea prognozei, trebuie să decidă asupra coeficientului α, de care depinde foarte mult calitatea prognozei. Iată un astfel de cerc vicios.
clar

Figura 2. α =0,2 , gradul de netezire exponențială este ridicat, vânzările reale sunt slab luate în considerare

Figura 3. α =0,4 , gradul de netezire exponențială este mediu, vânzările reale sunt luate în considerare în gradul mediu
Puteți vedea cum, pe măsură ce constanta α crește, seria netezită se potrivește din ce în ce mai mult cu vânzările reale, iar dacă există valori aberante sau anomalii, vom obține o prognoză foarte inexactă.

Figura 4. α =0,6 , gradul de netezire exponențială este scăzut, vânzările reale sunt luate în considerare semnificativ
Putem observa că la α=0,8, seria o repetă aproape exact pe cea inițială, ceea ce înseamnă că prognoza tinde spre regula „se va vinde aceeași sumă ca și ieri”
Trebuie remarcat faptul că aici este absolut imposibil să ne concentrăm pe eroarea de aproximare a datelor originale. Puteți obține o potrivire perfectă, dar obțineți o predicție inacceptabilă.

Figura 5. α = 0,8 , gradul de netezire exponențială este extrem de scăzut, vânzările reale sunt luate în considerare puternic
Exemple de prognoză
Acum să ne uităm la predicțiile care se fac folosind sensuri diferite A. După cum se poate observa din figurile 6 și 7, cu cât coeficientul de netezire este mai mare, cu atât mai precis repetă vânzările reale cu o întârziere de un pas, prognoza. O astfel de întârziere poate fi de fapt critică, așa că nu puteți alege pur și simplu valoarea maximă a lui α. În caz contrar, vom ajunge la o situație în care spunem că se va vinde exact cât s-a vândut în perioada anterioară.

Figura 6. Predicția metodei de netezire exponențială pentru α=0,2

Figura 7. Predicția metodei de netezire exponențială pentru α=0,6
Să vedem ce se întâmplă când α = 1,0. Amintiți-vă că S - vânzări prezise (netezite), C - vânzări reale.
S (t+1) = (1 -α )* S (t) +α * CU (t).
S (t+1) = CU (t).
Vânzările din ziua t+1 sunt estimate a fi egale cu vânzările din ziua precedentă. Prin urmare, alegerea unei constante trebuie abordată cu înțelepciune.
Comparație cu Prognoza ACUM!
Acum luați în considerare această metodă de prognoză în comparație cu Prognoza ACUM!. Comparația a fost efectuată pe 256 de produse care au vânzări diferite, cu sezonalitate pe termen scurt și lung, cu vânzări și lipsuri „proaste”, stocuri și alte valori aberante. Pentru fiecare produs s-a construit o prognoză folosind modelul de netezire exponențială, pentru diverse α, cea mai bună a fost selectată și comparată cu prognoza folosind Forecast NOW!
În tabelul de mai jos, puteți vedea valoarea erorii de prognoză pentru fiecare produs. Eroarea aici a fost considerată RMSE. Aceasta este rădăcina deviație standard predicție din realitate. Aproximativ, arată cu câte unități de mărfuri am deviat în prognoză. Îmbunătățirea arată cu cât la sută Prognoza ACUM! este mai bine dacă numărul este pozitiv și mai rău dacă este negativ. În Figura 8, axa x arată mărfuri, axa y indică cât de mult este Prognoza ACUM! mai bună decât predicția de netezire exponențială. După cum puteți vedea din acest grafic, Prognoza ACUM! aproape întotdeauna de două ori mai mare și aproape niciodată mai rău. În practică, aceasta înseamnă că folosind Forecast NOW! va permite reducerea la jumătate a stocurilor sau reducerea penuriei.
Identificarea și analiza tendinței unei serii de timp se face adesea cu ajutorul alinierii sau netezirii acesteia. Netezirea exponențială este una dintre cele mai simple și mai comune tehnici de aliniere a seriei. Netezirea exponențială poate fi reprezentată ca un filtru, a cărui intrare este recepționată succesiv de membrii seriei originale, iar valorile curente ale mediei exponențiale sunt formate la ieșire.
Să fie o serie de timp.
Netezirea exponenţială a seriei se realizează după formula recurentă: , .
Cu cât α este mai mic, cu atât fluctuațiile seriei originale și zgomotul sunt mai filtrate și suprimate.
Dacă această relație recursivă este utilizată în mod consecvent, atunci media exponențială poate fi exprimată în termeni de valori ale seriei temporale X.
Dacă există date anterioare în momentul în care începe netezirea, atunci media aritmetică a tuturor sau a unora dintre datele disponibile poate fi utilizată ca valoare inițială.
După apariția lucrărilor lui R. Brown, netezirea exponențială este adesea folosită pentru a rezolva problema prognozării pe termen scurt a seriilor temporale.
Formularea problemei
Să fie dat seria temporală: .
Este necesar să se rezolve problema prognozării seriilor temporale, adică. găsi
Orizontul de prognoză, este necesar ca
Pentru a lua în considerare învechirea datelor, introducem o secvență necrescătoare de ponderi, apoi
Model maro
Să presupunem că D este mic (prognoză pe termen scurt), apoi pentru a rezolva o astfel de problemă, folosiți model maro.
Dacă luăm în considerare prognoza cu un pas înainte, atunci - eroarea acestei prognoze, iar noua prognoză se obține ca urmare a ajustării prognozei anterioare, ținând cont de eroarea acesteia - esența adaptării.
În prognoza pe termen scurt, este de dorit să reflectăm noile schimbări cât mai repede posibil și, în același timp, să „curățați” seria de fluctuații aleatorii cât mai bine posibil. Acea. creste ponderea observatiilor mai recente: .
Pe de altă parte, pentru a netezi abaterile aleatoare, α trebuie redus: .
Acea. aceste două cerințe sunt în conflict. Căutarea unei valori de compromis a α este problema optimizării modelului. De obicei, α este luat din intervalul (0,1/3).
Exemple

Lucrări de netezire exponențială la α=0,2 pe datele rapoartelor lunare privind vânzările unei mărci de mașini străine în Rusia pentru perioada ianuarie 2007 până în octombrie 2008. Observăm scăderi puternice în ianuarie și februarie, când vânzările în mod tradițional scad și cresc la începutul anului. vară.
Probleme
Modelul funcționează doar cu un orizont mic de prognoză. Schimbările de tendințe și sezoniere nu sunt luate în considerare. Pentru a ține cont de influența acestora, se propune utilizarea următoarelor modele: Holt (se ia în considerare tendința liniară), Holt-Winters (tendința exponențială multiplicativă și sezonalitatea), Theil-Wage (tendința liniară aditivă și sezonalitatea).
9 5. Metoda netezirii exponenţiale. Selectarea unei constante de netezire
Când utilizați metoda cele mai mici pătrate pentru a determina tendința (tendința) predictivă, se presupune în prealabil că toate datele (observațiile) retrospective au același conținut informațional. Evident, mai logic ar fi să se țină cont de procesul de decontare a informațiilor inițiale, adică de valoarea inegală a acestor date pentru elaborarea unei prognoze. Acest lucru se realizează în metoda de netezire exponențială prin acordarea ultimelor observații ale seriei temporale (adică valorilor imediat premergătoare perioadei de previziune) mai semnificative „ponderi” față de observațiile inițiale. Avantajele metodei de netezire exponențială ar trebui să includă, de asemenea, simplitatea operațiilor de calcul și flexibilitatea descrierii diferitelor dinamici de proces. Metoda a găsit cea mai mare aplicație pentru implementarea previziunilor pe termen mediu.
5.1. Esența metodei de netezire exponențială
Esența metodei este că seria temporală este netezită folosind o „medie mobilă” ponderată, în care ponderile respectă legea exponențială. Cu alte cuvinte, cu cât este mai departe de sfârșitul seriei temporale punctul pentru care se calculează media mobilă ponderată, cu atât este mai puțină „participarea” la elaborarea prognozei.
Fie seria dinamică originală formată din niveluri (componente serie) y t , t = 1 , 2 ,...,n . Pentru fiecare m niveluri succesive ale acestei serii
(m serie dinamică cu un pas egal cu unu. Dacă m este un număr impar și este de preferat să luați un număr impar de niveluri, deoarece în acest caz valoarea nivelului calculată va fi în centrul intervalului de netezire și este ușor să înlocuiți valoarea reală cu aceasta, atunci se poate scrie următoarea formulă pentru a determina media mobilă: t+ ξ t+ ξ ∑ y i ∑ y i i= t−ξ i= t−ξ 2ξ + 1 unde y t este valoarea mediei mobile pentru momentul t (t = 1 , 2 ,...,n ); y i este valoarea reală a nivelului în momentul i ; i este numărul ordinal al nivelului în intervalul de netezire. Valoarea lui ξ este determinată din durata intervalului de netezire. Deoarece m =2 ξ +1 pentru m impar, atunci ξ = m 2 − 1 . Calcularea mediei mobile pentru un număr mare de niveluri poate fi simplificată prin definirea valorilor succesive ale mediei mobile în mod recursiv: y t= y t− 1 + yt + ξ − y t − (ξ + 1) 2ξ + 1 Dar dat fiind faptul că ultimele observații trebuie să li se acorde mai multă „pondere”, media mobilă trebuie interpretată diferit. Constă în faptul că valoarea obţinută prin mediere înlocuieşte nu termenul central al intervalului de mediere, ci ultimul său termen. În consecință, ultima expresie poate fi rescrisă ca Mi = Mi + 1 y i− y i− m Aici media mobilă, raportată la sfârșitul intervalului, este notă cu noul simbol M i . În esență, M i este egal cu y t deplasat ξ pași spre dreapta, adică M i = y t + ξ , unde i = t + ξ . Considerând că M i − 1 este o estimare a lui y i − m , expresia (5.1) poate fi rescris sub formă y i+ 1 M i - 1 , M i definit prin expresia (5.1). unde M i este estimarea Dacă calculele (5.2) sunt repetate pe măsură ce sosesc informații noi și rescriem într-o formă diferită, apoi obținem o funcție de observație netezită: Q i= α y i+ (1 − α ) Q i− 1 , sau în formă echivalentă Q t= α y t+ (1 − α ) Q t− 1 Calculele efectuate prin expresia (5.3) cu fiecare nouă observație se numesc netezire exponențială. În ultima expresie, pentru a distinge netezirea exponențială de media mobilă, se introduce notația Q în loc de M . Valoarea α , care este analogul lui m 1 se numește constantă de netezire. Valorile lui α se află în intervalul [ 0 , 1 ] . Dacă α este reprezentat ca o serie α + α(1 − α) + α(1 − α) 2 + α(1 − α) 3 + ... + α(1 − α) n , este ușor de observat că „greutățile” scad exponențial în timp. De exemplu, pentru α = 0 , 2 obținem 0,2 + 0,16 + 0,128 + 0,102 + 0,082 + … Suma seriei tinde spre unitate, iar termenii sumei scad cu timpul. Valoarea lui Q t în expresia (5.3) este media exponenţială de ordinul întâi, adică media obţinută direct din netezirea datelor de observație (netezire primară). Uneori, la dezvoltarea modelelor statistice este util să se recurgă la calculul mediilor exponențiale de ordine superioare, adică medii obținute prin netezire exponențială repetată. Notatia generala in forma recursiva a mediei exponentiale de ordin k este Q t (k)= α Q t (k− 1 )+ (1 − α ) Q t (− k1 ). Valoarea lui k variază în intervalul 1, 2, …, p ,p+1 , unde p este ordinea polinomului predictiv (liniar, pătratic și așa mai departe). Pe baza acestei formule, pentru media exponențială a ordinului I, II și III, expresiile Q t (1 )= α y t + (1 − α ) Q t (− 1 1 ); Q t (2 )= α Q t (1 )+ (1 − α ) Q t (− 2 1 ); Q t (3 )= α Q t (2 )+ (1 − α ) Q t (− 3 1 ). 5.2. Determinarea parametrilor modelului predictiv folosind metoda de netezire exponențială Evident, pentru a dezvolta valori predictive bazate pe seria dinamică folosind metoda de netezire exponențială, este necesar să se calculeze coeficienții ecuației de tendință prin medii exponențiale. Estimările coeficienților sunt determinate de teorema fundamentală a lui Brown-Meyer, care leagă coeficienții polinomului predictiv cu mediile exponențiale ale ordinelor corespunzătoare: (−
1
) aˆ p α (1 − α )∞ −α
)
j (p − 1 + j ) ! ∑ j p=0 p! (k− 1 ) !j = 0 unde aˆ p sunt estimări ale coeficienților polinomului de gradul p . Coeficienții se găsesc prin rezolvarea sistemului (p + 1 ) de ecuații сp + 1 necunoscut. Deci, pentru un model liniar aˆ 0 = 2 Q t (1) − Q t (2) ; aˆ 1 = 1 − α α (Q t (1 )− Q t (2 )) ; pentru un model patratic aˆ 0 = 3 (Q t (1 )− Q t (2 )) + Q t (3 ); aˆ 1 =1 − α α [ (6 −5 α ) Q t (1 ) −2 (5 −4 α ) Q t (2 ) +(4 −3 α ) Q t (3 ) ] ; aˆ 2 = (1 − α α ) 2 [ Q t (1 )− 2 Q t (2 )+ Q t (3 )] . Prognoza este implementată conform polinomului selectat, respectiv, pentru modelul liniar ˆyt + τ = aˆ0 + aˆ1 τ ; pentru un model patratic ˆyt + τ = aˆ0 + aˆ1 τ + aˆ 2 2 τ 2 , unde τ este pasul de predicție. De remarcat că mediile exponenţiale Q t (k ) pot fi calculate numai cu un parametru cunoscut (ales), cunoscând condiţiile iniţiale Q 0 (k ) . Estimări ale condițiilor inițiale, în special, pentru un model liniar Q(1)=a 1 − α Q(2 ) = a − 2 (1 − α ) a pentru un model patratic Q(1)=a 1 − α + (1 − α )(2 − α ) a 2(1−α ) (1− α )(3− 2α ) Q 0(2 ) = a 0− 2α 2 Q(3)=a 3(1−α ) (1 − α )(4 − 3 α ) a unde coeficienții a 0 și a 1 se calculează prin metoda celor mai mici pătrate. Valoarea parametrului de netezire α este calculată aproximativ prin formulă α ≈ m 2 + 1, unde m este numărul de observații (valori) din intervalul de netezire. Secvența de calcul a valorilor predictive este prezentată în Calculul coeficienților unei serii prin metoda celor mai mici pătrate Determinarea intervalului de netezire Calculul constantei de netezire Calculul condițiilor inițiale Calcularea mediilor exponențiale Calculul estimărilor a 0 , a 1 , etc. Calculul valorilor prognozate ale unei serii Orez. 5.1. Secvența de calcul a valorilor prognozate Ca exemplu, luați în considerare procedura de obținere a valorii predictive a timpului de funcționare a produsului, exprimată prin timpul dintre defecțiuni. Datele inițiale sunt rezumate în tabel. 5.1. Alegem un model de prognoză liniară sub forma y t = a 0 + a 1 τ Soluția este fezabilă cu următoarele valori inițiale: a 0, 0 = 64, 2; a1, 0 = 31,5; a = 0,305. Tabelul 5.1. Datele inițiale Numărul de observație, t Lungimea pasului, predicție, τ MTBF, y (oră) Pentru aceste valori, coeficienții „neteziți” calculati pentru y 2 valori vor fi egale = α Q (1 )− Q (2 )= 97 , 9 ; [ Q (1 ) − Q (2 ) 31,
9 , 1−α în condiţii iniţiale 1 − α A 0 , 0 - a 1, 0 = −7
,
6
1 − α = −79
,
4
și medii exponențiale Q (1 )= α y + (1 − α ) Q (1 ) 25,
2;
Î(2) = α Q (1) + (1 −α ) Q (2 ) = −47 , 5 . Valoarea „netezită” y 2 este apoi calculată prin formula Q i (1) Q i (2 ) a 0,i a 1,i YT Astfel (Tabelul 5.2), modelul predictiv liniar are forma ˆy t + τ = 224,5+ 32τ . Să calculăm valorile prezise pentru perioadele de plumb de 2 ani (τ = 1 ), 4 ani (τ = 2 ) și așa mai departe, timpul dintre defecțiunile produsului (Tabelul 5.3). Tabelul 5.3. Valorile prognozate ˆy t Ecuația t+2 t+4 t+6 t+8 t+20 regresie (τ = 1) (τ=2) (τ = 3) (τ=5) τ =
ˆy t = 224,5+ 32τ Trebuie remarcat faptul că „greutatea” totală a ultimelor m valori ale seriei temporale poate fi calculată prin formula c = 1 − (m (− 1 ) m ) . m+ 1 Astfel, pentru ultimele două observații ale seriei (m = 2 ) valoarea c = 1 − (2 2 − + 1 1 ) 2 = 0. 667 . 5.3. Alegerea condițiilor inițiale și determinarea constantei de netezire După cum rezultă din expresie Q t= α y t+ (1 − α ) Q t− 1 , la efectuarea netezirii exponentiale este necesar sa se cunoasca valoarea initiala (anterioara) a functiei netezite. În unele cazuri, prima observație poate fi luată ca valoare inițială; mai des, condițiile inițiale sunt determinate conform expresiilor (5.4) și (5.5). În acest caz, valorile a 0 , 0 ,a 1 , 0 și a 2 , 0 sunt determinate prin metoda celor mai mici pătrate. Dacă nu avem cu adevărat încredere în valoarea inițială aleasă, atunci luând o valoare mare a constantei de netezire α prin k observații, vom aduce „greutatea” valorii inițiale până la valoarea (1 − α ) k<<
α
, и оно будет практически забыто. Наоборот, если мы уверены в правильности выбранного начального значения и неизменности модели в течение определенного отрезка времени в будущем,α
может быть выбрано малым (близким к 0). Astfel, alegerea constantei de netezire (sau a numărului de observații din media mobilă) implică un compromis. De obicei, după cum arată practica, valoarea constantei de netezire se află în intervalul de la 0,01 la 0,3. Sunt cunoscute mai multe tranziții care permit să se găsească o estimare aproximativă a lui α . Prima rezultă din condiția ca media mobilă și media exponențială să fie egale α \u003d m 2 + 1, unde m este numărul de observații din intervalul de netezire. Alte abordări sunt asociate cu acuratețea prognozei. Deci, este posibil să se determine α pe baza relației Meyer: α ≈ S y , unde S y este eroarea standard a modelului; S 1 este eroarea pătratică medie a seriei originale. Cu toate acestea, utilizarea celui din urmă raport este complicată de faptul că este foarte dificil să se determine în mod fiabil S y și S 1 din informațiile inițiale. Adesea parametrul de netezire și, în același timp, coeficienții a 0 , 0 și a 0 , 1 sunt selectate ca optime în funcţie de criteriu S 2 = α ∑ ∞ (1 − α ) j [ yij − ˆyij ] 2 → min j=0 prin rezolvarea sistemului algebric de ecuații, care se obține prin egalarea derivatelor la zero ∂S2 ∂S2 ∂S2 ∂a0, 0 ∂ a 1, 0 ∂a2, 0 Deci, pentru un model de prognoză liniară, criteriul inițial este egal cu S 2 = α ∑ ∞ (1 − α ) j [ yij − a0 , 0 − a1 , 0 τ ] 2 → min. j=0 Rezolvarea acestui sistem cu ajutorul unui calculator nu prezintă dificultăți. Pentru o alegere rezonabilă a lui α, puteți utiliza și procedura de netezire generalizată, care vă permite să obțineți următoarele relații referitoare la varianța prognozei și parametrul de netezire pentru un model liniar: S p 2 ≈[ 1 + α β ] 2 [ 1 +4 β +5 β 2 +2 α (1 +3 β ) τ +2 α 2 τ 3 ] S y 2 pentru un model patratic S p 2≈ [ 2 α + 3 α 3+ 3 α 2τ ] S y 2, unde β =
1
−
α
;Sy– Aproximarea RMS a seriei dinamice inițiale. Sarcinile de prognoză se bazează pe modificarea unor date în timp (vânzări, cerere, ofertă, PIB, emisii de carbon, populație...) și proiectarea acestor schimbări în viitor. Din păcate, tendințele identificate pe baza datelor istorice pot fi perturbate de o varietate de circumstanțe neprevăzute. Deci datele din viitor pot diferi semnificativ de ceea ce sa întâmplat în trecut. Aceasta este problema cu prognoza. Cu toate acestea, există tehnici (numite netezire exponențială) care permit nu doar încercarea de a prezice viitorul, ci și exprimarea numerică a incertitudinii a tot ceea ce are legătură cu prognoza. Exprimarea numerică a incertitudinii prin crearea de intervale de prognoză este cu adevărat neprețuită, dar adesea trecută cu vederea în lumea prognozelor. Descărcați nota în sau format, exemple în format Să presupunem că ești un fan al Stăpânului Inelelor și că faci și vinzi săbii de trei ani (Figura 1). Să afișăm grafic vânzările (Fig. 2). Cererea s-a dublat în trei ani - poate aceasta este o tendință? Vom reveni la această idee puțin mai târziu. Există mai multe vârfuri și văi pe diagramă, ceea ce poate fi un semn de sezonalitate. În special, vârfurile sunt în lunile 12, 24 și 36, care se întâmplă să fie decembrie. Dar poate e doar o coincidență? Să aflăm. Metodele de netezire exponențială se bazează pe prezicerea viitorului din datele din trecut, unde observațiile mai noi cântăresc mai mult decât cele mai vechi. O astfel de ponderare este posibilă datorită constantelor de netezire. Prima metodă de netezire exponențială pe care o vom încerca se numește netezire exponențială simplă (SES). Utilizează o singură constantă de netezire. Netezirea exponențială simplă presupune că seria temporală a datelor are două componente: un nivel (sau o medie) și o eroare în jurul valorii respective. Nu există tendințe sau fluctuații sezoniere - există doar un nivel în jurul căruia cererea fluctuează, înconjurată de mici erori ici și colo. Prin acordarea de preferință observațiilor mai noi, TEC poate provoca schimbări la acest nivel. În limbajul formulelor, Cererea la momentul t = nivel + eroare aleatorie în jurul nivelului la momentul t Deci, cum găsești valoarea aproximativă a nivelului? Dacă acceptăm toate valorile de timp ca având aceeași valoare, atunci ar trebui să calculăm pur și simplu valoarea lor medie. Cu toate acestea, aceasta este o idee proastă. Ar trebui acordată mai multă importanță observațiilor recente. Să creăm niște niveluri. Calculați valoarea de referință pentru primul an: nivelul 0 = cererea medie pentru primul an (lunile 1-12) Pentru cererea de sabie, este 163. Utilizăm nivelul 0 (163) ca prognoză a cererii pentru luna 1. Cererea în luna 1 este 165, care este cu 2 săbii peste nivelul 0. Merită să actualizați aproximarea liniei de bază. Ecuație simplă de netezire exponențială: nivelul 1 = nivelul 0 + câteva procente × (cererea 1 - nivelul 0) nivelul 2 = nivelul 1 + câteva procente × (cererea 2 - nivelul 1) etc. „Câteva procente” se numește constantă de netezire și este notat cu alfa. Poate fi orice număr de la 0 la 100% (de la 0 la 1). Veți învăța cum să alegeți o valoare alfa mai târziu. În general, valoarea pentru diferite momente în timp: Nivel perioada curentă = nivel perioada anterioară + Cererea viitoare este egală cu ultimul nivel calculat (Fig. 3). Deoarece nu știți ce este alfa, setați celula C2 la 0,5 pentru început. După ce modelul este construit, găsiți un alfa astfel încât suma pătratelor erorii - E2 (sau abaterea standard - F2) să fie minimă. Pentru a face acest lucru, rulați opțiunea Găsirea unei soluții. Pentru a face acest lucru, treceți prin meniu DATE –> Găsirea unei soluțiiși setați în fereastră Opțiuni de căutare a soluției valorile cerute (Fig. 4). Pentru a afișa rezultatele prognozei pe grafic, selectați mai întâi intervalul A6:B41 și construiți o diagramă cu linii simplă. Apoi, faceți clic dreapta pe diagramă, selectați opțiunea Selectați datele.În fereastra care se deschide, creați un al doilea rând și introduceți predicții din intervalul A42:B53 în el (Fig. 5). Pentru a testa această ipoteză, este suficient să potriviți o regresie liniară la datele cererii și să efectuați un test t Student pe creșterea acestei linii de tendință (ca în ). Dacă panta dreptei este diferită de zero și semnificativă statistic (în testul Student, valoarea R mai mică de 0,05), datele au o tendință (Fig. 6). Am folosit funcția LINEST, care returnează 10 statistici descriptive (dacă nu ați folosit această funcție înainte, vă recomand) și funcția INDEX, care vă permite să „trageți” doar cele trei statistici necesare, și nu întregul set. S-a dovedit că panta este de 2,54 și este semnificativă, deoarece testul Student a arătat că 0,000000012 este semnificativ mai mică decât 0,05. Deci, există o tendință și rămâne să o includem în prognoză. Este adesea denumită netezire dublă exponențială deoarece are doi parametri de netezire, alfa, mai degrabă decât unul. Dacă secvența de timp are o tendință liniară, atunci: cererea la momentul t = nivelul + t × tendință + abaterea aleatorie a nivelului la momentul t Holt Exponential Smoothing cu corecția tendinței are două ecuații noi, una pentru nivelul pe măsură ce avansează în timp și cealaltă pentru tendință. Ecuația de nivel conține parametrul de netezire alfa, iar ecuația de tendință conține gamma. Iată cum arată ecuația noului nivel: nivel 1 = nivel 0 + tendință 0 + alfa × (cerere 1 - (nivel 0 + tendință 0)) Rețineți că nivelul 0 + tendința 0 este doar o prognoză într-un singur pas de la valorile originale până la luna 1, deci cerere 1 – (nivel 0 + tendință 0) este o abatere într-un singur pas. Astfel, ecuația de aproximare a nivelului de bază va fi după cum urmează: nivelul perioadei curente = nivelul perioadei anterioare + tendința perioadei anterioare + alpha × (cererea perioadei curente - (nivelul perioadei precedente) + tendința perioadei anterioare)) Ecuația de actualizare a tendinței: tendință perioada curentă = tendință perioada anterioară + gamma × alfa × (cerere perioada curentă – (nivel perioada anterioară) + tendință perioada anterioară)) Netezirea Holt în Excel este similară cu netezirea simplă (Fig. 7) și, ca mai sus, scopul este de a găsi doi coeficienți minimizând în același timp suma erorilor pătrate (Fig. 8). Pentru a obține nivelul inițial și valorile tendinței (în celulele C5 și D5 din Figura 7), creați un grafic pentru primele 18 luni de vânzări și adăugați o linie de tendință cu o ecuație. Introduceți valoarea inițială a tendinței de 0,8369 și nivelul inițial de 155,88 în celulele C5 și D5. Datele de prognoză pot fi prezentate grafic (Fig. 9). Orez. 7. Netezirea Holt exponențială cu corecția tendinței; Pentru a mări o imagine, faceți clic dreapta pe ea și selectați Deschide imaginea într-o filă nouă Există o modalitate de a testa modelul predictiv pentru putere - de a compara erorile cu ele însele, deplasate cu un pas (sau mai mulți pași). Dacă abaterile sunt aleatorii, atunci modelul nu poate fi îmbunătățit. Cu toate acestea, poate exista un factor sezonier în datele privind cererea. Conceptul de eroare care se corelează cu propria sa versiune într-o perioadă diferită se numește autocorelare (pentru mai multe despre autocorelare, vezi ). Pentru a calcula autocorelația, începeți cu datele de eroare de prognoză pentru fiecare perioadă (transferați coloana F din Figura 7 în coloana B din Figura 10). Apoi, determinați eroarea medie de prognoză (Figura 10, celula B39; formula în celulă: = MEDIA(B3:B38)). În coloana C, se calculează abaterea erorii de prognoză de la medie; formula în celula C3: =B3-B$39. Apoi, mutați secvențial coloana C o coloană la dreapta și un rând în jos. Formule din celulele D39: =SUMPRODUCT($C3:$C38,D3:D38), D41: =D39/$C39, D42: =2/SQRT(36), D43: =-2/SQRT(36). Ce poate însemna „mișcarea sincronă” cu coloana C pentru una dintre coloanele D: O. De exemplu, dacă coloanele C și D sunt sincrone, atunci un număr care este negativ într-una dintre ele trebuie să fie negativ în cealaltă, pozitiv într-una , pozitiv în prieten. Aceasta înseamnă că suma produselor celor două coloane va fi semnificativă (se acumulează diferențele). Sau, ceea ce este același, cu cât valoarea din intervalul D41:O41 este mai aproape de zero, cu atât este mai mică corelația coloanei (respectiv de la D la O) cu coloana C (Fig. 11). O autocorelație este peste valoarea critică. Eroarea deplasată pe an se corelează cu ea însăși. Aceasta înseamnă un ciclu sezonier de 12 luni. Și acest lucru nu este surprinzător. Dacă te uiți la graficul cererii (Figura 2), se dovedește că există vârfuri ale cererii în fiecare Crăciun și scăderi în aprilie-mai. Luați în considerare o tehnică de prognoză care ține cont de sezonalitate. Metoda se numește multiplicativă (din multiplicare - înmulțire), deoarece folosește înmulțirea pentru a ține cont de sezonalitate: Cererea la momentul t = (nivel + t × tendință) × ajustarea sezonieră la momentul t × orice ajustări neregulate rămase pe care nu le putem explica Netezirea Holt-Winters este numită și netezire triplă exponențială deoarece are trei parametri de netezire (factor sezonier alfa, gamma și delta). De exemplu, dacă există un ciclu sezonier de 12 luni: Prognoza lunară 39 = (nivel 36 + 3 × tendință 36) x sezonalitate 27 Atunci când se analizează datele, este necesar să se afle care este tendința în seria de date și care este sezonalitatea. Pentru a efectua calcule folosind metoda Holt-Winters, trebuie să: Începeți cu datele originale (coloanele A și B din Figura 12) și adăugați coloana C cu valori netezite pe baza mediei mobile. Deoarece sezonalitatea are cicluri de 12 luni, este logic să folosiți o medie de 12 luni. Există o mică problemă cu această medie. 12 este un număr par. Dacă uniformizați cererea pentru luna 7, ar trebui să fie considerată cererea medie din lunile 1 la 12 sau de la 2 la 13? Pentru a face față acestei dificultăți, trebuie să netezim cererea folosind o „medie mobilă 2x12”. Adică, luați jumătate din cele două medii de la lunile 1 la 12 și de la 2 la 13. Formula din celula C8 este: =(MEDIA(B3:B14)+MEDIA(B2:B13))/2. Datele netezite pentru lunile 1–6 și 31–36 nu pot fi obținute deoarece nu există suficiente perioade anterioare și ulterioare. Pentru claritate, datele originale și netezite pot fi prezentate într-o diagramă (Fig. 13). Acum, în coloana D, împărțiți valoarea inițială la valoarea netezită pentru a obține o estimare a ajustării sezoniere (coloana D din Figura 12). Formula în celula D8: =B8/C8. Observați creșteri cu 20% peste cererea normală în lunile 12 și 24 (decembrie), în timp ce sunt scăderi în primăvară. Această tehnică de netezire v-a oferit două estimări de puncte pentru fiecare lună (24 de luni în total). Coloana E este media acestor doi factori. Formula din celula E1 este: =AVERAGE(D14,D26). Pentru claritate, nivelul fluctuațiilor sezoniere poate fi reprezentat grafic (Fig. 14). Acum puteți obține date ajustate sezonier. Formula în celula G1: =B2/E2. Construiți un grafic pe baza datelor din coloana G, completați-l cu o linie de tendință, afișați ecuația tendinței pe diagramă (Fig. 15) și utilizați coeficienții în calculele ulterioare. Formați o foaie nouă așa cum se arată în fig. 16. Înlocuiți valorile din intervalul E5:E16 din fig. 12 zone E2:E13. Luați valorile C16 și D16 din ecuația liniei de tendință din fig. 15. Setați valorile constantelor de netezire să înceapă de la aproximativ 0,5. Extindeți valorile din rândul 17 în intervalul lunilor 1 până la 36. Rulați Găsirea unei soluții pentru a optimiza coeficienții de netezire (Fig. 18). Formula în celula B53: =(C$52+(A53-A$52)*D$52)*E41. Acum, în prognoza făcută, trebuie să verificați autocorelațiile (Fig. 18). Deoarece toate valorile sunt situate între limitele superioare și inferioare, înțelegeți că modelul a făcut o treabă bună în înțelegerea structurii valorilor cererii. Deci, avem o prognoză destul de funcțională. Cum setați limitele superioare și inferioare care pot fi folosite pentru a face presupuneri realiste? Simularea Monte Carlo, pe care ați întâlnit-o deja (vezi și ), vă va ajuta în acest sens. Ideea este de a genera scenarii viitoare de comportament al cererii și de a determina grupul în care se încadrează 95% dintre aceștia. Eliminați prognoza din celulele B53:B64 din foaia Excel (vezi Fig. 17). Veți scrie cererea acolo pe baza simulării. Acesta din urmă poate fi generat folosind funcția NORMINV. Pentru lunile viitoare, trebuie doar să îi furnizați media (0), distribuția standard (10,37 din celula $H$2) și un număr aleatoriu între 0 și 1. Funcția va returna abaterea cu o probabilitate corespunzătoare clopoțelului curba. Puneți o simulare a erorii într-un singur pas în celula G53: =NORMINV(RAND();0;H$2). Extinderea acestei formule până la G64 vă oferă simulări ale erorii de prognoză pentru o prognoză cu un pas pe 12 luni (Figura 19). Valorile dvs. de simulare vor diferi de cele prezentate în figură (de aceea este o simulare!). Cu Forecast Error, aveți tot ce aveți nevoie pentru a actualiza nivelul, tendința și factorul sezonier. Așadar, selectați celulele C52:F52 și întindeți-le la rândul 64. Ca rezultat, aveți o eroare de prognoză simulată și prognoza în sine. Mergând de la opus, este posibil să se prezică valorile cererii. Introduceți formula în celula B53: =F53+G53 și întindeți-o la B64 (Fig. 20, interval B53:F64). Acum puteți apăsa butonul F9, actualizând de fiecare dată prognoza. Plasați rezultatele a 1000 de simulări în celulele A71:L1070, transpunând de fiecare dată valori din intervalul B53:B64 în intervalul A71:L71, A72:L72, ... A1070:L1070. Dacă vă deranjează, scrieți codul VBA. Acum aveți 1000 de scenarii pentru fiecare lună și puteți utiliza funcția PERCENTILĂ pentru a obține limitele superioare și inferioare la mijlocul intervalului de încredere de 95%. În celula A66, formula este: =PERCENTIL(A71:A1070,0,975) iar în celula A67: =PERCENTIL(A71:A1070,0,025). Ca de obicei, pentru claritate, datele pot fi prezentate sub formă grafică (Fig. 21). Există două puncte interesante pe diagramă: Bazat pe material dintr-o carte de John Foreman. – M.: Editura Alpina, 2016. – S. 329–381 Dezvoltarea de noi și analiza tehnologiilor de management bine-cunoscute care îmbunătățesc eficiența managementului afacerilor devin deosebit de relevante pentru întreprinderile rusești în prezent. Unul dintre cele mai populare instrumente este sistemul de bugetare, care se bazează pe formarea bugetului întreprinderii cu controlul ulterior asupra execuției. Bugetul este un plan echilibrat pe termen scurt comercial, de producție, financiar și economic pentru dezvoltarea organizației. Bugetul companiei conține obiective care sunt calculate pe baza datelor de prognoză. Cea mai semnificativă prognoză de buget pentru orice afacere este prognoza vânzărilor. În articolele anterioare a fost efectuată o analiză a modelelor aditive și multiplicative și a fost calculat volumul de vânzări prognozat pentru perioadele următoare. La analiza seriilor temporale s-a folosit metoda mediei mobile, în care toate datele, indiferent de perioada de apariție a acestora, sunt egale. Există un alt mod în care ponderile sunt atribuite datelor, datele mai recente primesc mai multă pondere decât datele anterioare. Metoda de netezire exponențială, spre deosebire de metoda mediei mobile, poate fi utilizată și pentru prognozele pe termen scurt ale tendinței viitoare pentru o perioadă următoare și corectează automat orice prognoză în lumina diferențelor dintre rezultatul real și cel prezis. De aceea metoda are un avantaj clar față de cea considerată anterior. Denumirea metodei provine de la faptul că produce medii mobile ponderate exponențial pe întreaga serie de timp. Cu netezirea exponențială, se iau în considerare toate observațiile anterioare - cea anterioară este luată în considerare cu ponderea maximă, cea anterioară - cu una puțin mai mică, cea mai timpurie observație afectează rezultatul cu ponderea statistică minimă. Algoritmul pentru calcularea valorilor netezite exponențial în orice punct din seria i se bazează pe trei mărimi: valoarea reală a lui Ai într-un punct dat din rândul i, Noua prognoză poate fi scrisă astfel: Calculul valorilor netezite exponențial
În utilizarea practică a metodei de netezire exponențială, apar două probleme: alegerea factorului de netezire (W), care afectează în mare măsură rezultatele, și determinarea condiției inițiale (Fi). Pe de o parte, pentru a netezi abaterile aleatoare, valoarea trebuie redusă. Pe de altă parte, pentru a crește greutatea noilor măsurători, trebuie să creșteți. Deși, în principiu, W poate lua orice valoare din intervalul 0< W < 1, обычно ограничиваются интервалом от 0,2 до 0,5. При высоких значениях коэффициента сглаживания в большей степени учитываются мгновенные текущие наблюдения отклика (для динамично развивающихся фирм) и, наоборот, при низких его значениях сглаженная величина определяется в большей степени прошлой тенденцией развития, нежели текущим состоянием отклика системы (в условиях стабильного развития рынка). Alegerea factorului constant de netezire este subiectivă. Analiștii de la majoritatea firmelor își folosesc valorile tradiționale W atunci când procesează serii. Astfel, conform datelor publicate în departamentul analitic al Kodak, valoarea de 0,38 este utilizată în mod tradițional, iar la Ford Motors este de 0,28 sau 0,3. Calculul manual al netezirii exponențiale necesită o cantitate extrem de mare de muncă monotonă. De exemplu, să calculăm volumul prognozat pentru al 13-lea trimestru, dacă există date de vânzări pentru ultimele 12 trimestre, folosind metoda simplă de netezire exponențială. Să presupunem că pentru primul trimestru prognoza de vânzări a fost 3. Și să fie factorul de netezire W = 0,8. Completați a treia coloană din tabel, înlocuind pentru fiecare trimestru următor valoarea celui precedent după formula: Pentru 2 sferturi F2 = 0,8 * 4 (1-0,8) * 3 = 3,8 În mod similar, se calculează o valoare netezită pentru coeficientul 0,5 și 0,33. Previziunea pentru volumul vânzărilor la W = 0,8 pentru al 13-lea trimestru a fost de 13,3 mii de ruble. Aceste date pot fi prezentate sub formă grafică:


Datele inițiale

Netezire exponențială simplă
alpha × (cerere perioada curentă - nivel perioada anterioară)


Poate ai un trend

Netezire Holt exponențială cu corecția tendinței



Găsirea modelelor în date


Netezire Holt-Winters exponențială multiplicativă







Construirea unui interval de încredere pentru prognoză



Doctor în Economie, Director pentru Știință și Dezvoltare al CJSC „KIS”
Metoda de netezire exponențială
predicție într-un punct din seria Fi
un coeficient de netezire predeterminat W, constant pe tot parcursul seriei.
Pentru al 3-lea trimestru F3 =0,8*6 (1-0,8)*3,8 =5,6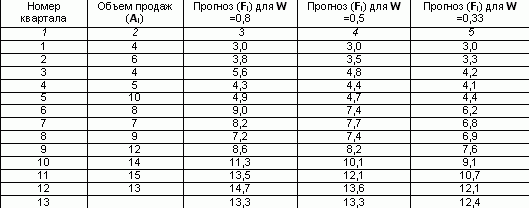
Calculul prognozei vânzărilor

Netezire exponențială



