การแจกแจงแบบทวินาม: ความหมาย สูตร ตัวอย่าง การแจกแจงแบบทวินามของตัวแปรสุ่ม
สวัสดีผู้อ่านทุกคน!
อย่างที่คุณทราบ การวิเคราะห์ทางสถิติเกี่ยวข้องกับการรวบรวมและประมวลผลข้อมูลจริง มันมีประโยชน์และมักจะได้กำไรเพราะ ข้อสรุปที่ถูกต้องช่วยให้คุณหลีกเลี่ยงข้อผิดพลาดและความสูญเสียในอนาคต และบางครั้งก็คาดเดาอนาคตนี้ได้อย่างถูกต้อง ข้อมูลที่รวบรวมได้สะท้อนถึงสถานะของปรากฏการณ์ที่สังเกตได้ ข้อมูลมักจะเป็นตัวเลข (แต่ไม่ใช่เสมอไป) และสามารถจัดการได้ด้วยการดัดแปลงทางคณิตศาสตร์ต่างๆ เพื่อดึงข้อมูลเพิ่มเติม
อย่างไรก็ตาม ไม่ใช่ว่าทุกปรากฏการณ์จะถูกวัดเป็นมาตราส่วนเชิงปริมาณ เช่น 1, 2, 3 ... 100500 ... ไม่ใช่ปรากฏการณ์เสมอไปที่จะเกิดขึ้นในสถานะต่างๆ ที่ไม่มีที่สิ้นสุดหรือจำนวนมาก ตัวอย่างเช่น เพศของบุคคลสามารถเป็นได้ทั้ง M หรือ F ผู้ยิงยิงเข้าเป้าหรือพลาด คุณสามารถลงคะแนนได้ทั้ง "สำหรับ" หรือ "ต่อต้าน" เป็นต้น เป็นต้น กล่าวอีกนัยหนึ่ง ข้อมูลดังกล่าวสะท้อนถึงสถานะของแอตทริบิวต์ทางเลือก - ไม่ว่าจะเป็น "ใช่" (เหตุการณ์เกิดขึ้น) หรือ "ไม่" (เหตุการณ์ไม่ได้เกิดขึ้น) เหตุการณ์ที่จะเกิดขึ้น (ผลลัพธ์เชิงบวก) เรียกอีกอย่างว่า "ความสำเร็จ" ปรากฏการณ์ดังกล่าวอาจมีขนาดใหญ่และสุ่ม ดังนั้นจึงสามารถวัดได้และสามารถสรุปผลที่ถูกต้องทางสถิติได้
การทดลองกับข้อมูลดังกล่าวเรียกว่า โครงการเบอร์นูลลีเพื่อเป็นเกียรติแก่นักคณิตศาสตร์ชาวสวิสผู้มีชื่อเสียงซึ่งตั้งขึ้นเมื่อนั้น ในจำนวนมากการทดลอง อัตราส่วนของผลลัพธ์ที่เป็นบวกและจำนวนการทดลองทั้งหมดมีแนวโน้มที่จะเกิดเหตุการณ์นี้ขึ้น
ตัวแปรคุณลักษณะสำรอง
ในการใช้เครื่องมือทางคณิตศาสตร์ในการวิเคราะห์ควรเขียนผลของการสังเกตดังกล่าวในรูปแบบตัวเลข ในการดำเนินการนี้ ผลลัพธ์เชิงบวกถูกกำหนดให้เป็นเลข 1 ซึ่งเป็นค่าลบ - 0 กล่าวอีกนัยหนึ่ง เรากำลังจัดการกับตัวแปรที่สามารถรับค่าได้เพียงสองค่าเท่านั้น: 0 หรือ 1
จะได้รับประโยชน์อะไรจากสิ่งนี้? ในความเป็นจริงไม่น้อยกว่าจากข้อมูลธรรมดา ดังนั้นจึงเป็นเรื่องง่ายที่จะนับจำนวนผลลัพธ์ที่เป็นบวก - แค่สรุปค่าทั้งหมดก็เพียงพอแล้ว เช่น ทั้งหมด 1 (สำเร็จ) คุณสามารถไปต่อได้ แต่สำหรับสิ่งนี้คุณต้องแนะนำสัญลักษณ์สองสามอย่าง
สิ่งแรกที่ควรทราบคือผลลัพธ์ที่เป็นบวก (ซึ่งเท่ากับ 1) มีความน่าจะเป็นที่จะเกิดขึ้น ตัวอย่างเช่น การโยนเหรียญออกหัวคือ ½ หรือ 0.5 ความน่าจะเป็นนี้แสดงแบบดั้งเดิม อักษรละติน หน้า. ดังนั้น ความน่าจะเป็นของเหตุการณ์อื่นที่เกิดขึ้นคือ 1 หน้าซึ่งแสดงด้วย ถาม, นั่นคือ คิว = 1 – หน้า. การกำหนดเหล่านี้สามารถจัดระบบด้วยสายตาในรูปแบบของแผ่นกระจายตัวแปร เอ็กซ์.
ตอนนี้เรามีรายการค่าที่เป็นไปได้และความน่าจะเป็น คุณสามารถเริ่มคำนวณลักษณะที่ยอดเยี่ยมดังกล่าวได้ ตัวแปรสุ่ม, ยังไง มูลค่าที่คาดหวังและ การกระจายตัว. ฉันขอเตือนคุณว่าความคาดหวังทางคณิตศาสตร์คำนวณเป็นผลรวมของผลคูณของค่าที่เป็นไปได้ทั้งหมดและความน่าจะเป็นที่สอดคล้องกัน:
![]()
ลองคำนวณค่าที่คาดหวังโดยใช้สัญกรณ์ในตารางด้านบน
ปรากฎว่าความคาดหวังทางคณิตศาสตร์ของเครื่องหมายทางเลือกเท่ากับความน่าจะเป็นของเหตุการณ์นี้ - หน้า.
ทีนี้มากำหนดความแปรปรวนของคุณสมบัติทางเลือกกัน ฉันขอเตือนคุณด้วยว่าความแปรปรวนคือค่าเฉลี่ยกำลังสองของความเบี่ยงเบนจากความคาดหวังทางคณิตศาสตร์ สูตรทั่วไป(สำหรับข้อมูลแยก) มีรูปแบบ:
ดังนั้นความแปรปรวนของคุณสมบัติทางเลือก:

ง่ายที่จะเห็นว่าการกระจายนี้มีสูงสุด 0.25 (ที่ พี=0.5).
ส่วนเบี่ยงเบนมาตรฐาน - รากของความแปรปรวน:
ค่าสูงสุดไม่เกิน 0.5
อย่างที่คุณเห็น ทั้งความคาดหวังทางคณิตศาสตร์และความแปรปรวนของเครื่องหมายทางเลือกมีรูปแบบที่กะทัดรัดมาก
การแจกแจงแบบทวินามของตัวแปรสุ่ม
พิจารณาสถานการณ์จากมุมที่ต่างออกไป แท้จริงแล้วใครจะสนใจว่าการสูญเสียหัวโดยเฉลี่ยในการโยนหนึ่งครั้งคือ 0.5 มันเป็นไปไม่ได้ที่จะจินตนาการ มันน่าสนใจกว่าที่จะตั้งคำถามเกี่ยวกับจำนวนหัวที่จะมาถึงสำหรับจำนวนการโยนที่กำหนด
กล่าวอีกนัยหนึ่ง ผู้วิจัยมักจะสนใจในความน่าจะเป็นของเหตุการณ์ที่ประสบความสำเร็จจำนวนหนึ่ง นี่อาจเป็นจำนวนของผลิตภัณฑ์ที่มีข้อบกพร่องในล็อตที่ทดสอบ (1 - มีข้อบกพร่อง 0 - ดี) หรือจำนวนของการกู้คืน (1 - สุขภาพดี 0 - ป่วย) เป็นต้น จำนวนของ "ความสำเร็จ" ดังกล่าวจะเท่ากับผลรวมของค่าทั้งหมดของตัวแปร เอ็กซ์, เช่น. จำนวนผลลัพธ์เดียว
ค่าสุ่ม ขเรียกว่าทวินามและรับค่าจาก 0 ถึง น(ที่ ข= 0 - ทุกส่วนดีด้วย ข = น-มีตำหนิทุกส่วน) ก็ถือว่ามีค่าทั้งหมด xเป็นอิสระจากกัน พิจารณาลักษณะสำคัญของตัวแปรทวินาม นั่นคือเราจะสร้างความคาดหวังทางคณิตศาสตร์ ความแปรปรวน และการแจกแจง
ความคาดหวังของตัวแปรทวินามนั้นหาได้ง่ายมาก จำไว้ว่ามีผลรวมของความคาดหวังทางคณิตศาสตร์ของมูลค่าเพิ่มแต่ละค่า และมันก็เหมือนกันสำหรับทุกคน ดังนั้น:
ตัวอย่างเช่น ความคาดหวังของจำนวนหัวในการทอย 100 ครั้งคือ 100 × 0.5 = 50
ตอนนี้เราได้สูตรสำหรับความแปรปรวนของตัวแปรทวินาม เป็นผลรวมของความแปรปรวน จากที่นี่
ส่วนเบี่ยงเบนมาตรฐาน ตามลำดับ
สำหรับการโยนเหรียญ 100 ครั้ง ค่าเบี่ยงเบนมาตรฐานคือ
และสุดท้าย พิจารณาการกระจาย ค่าทวินาม, เช่น. ความน่าจะเป็นที่ตัวแปรสุ่ม ขจะทำ ความหมายต่างๆ เค, ที่ไหน 0≤k≤n. สำหรับเหรียญ ปัญหานี้อาจมีลักษณะดังนี้ ความน่าจะเป็นที่จะออกหัว 40 ครั้งในการโยน 100 ครั้งเป็นเท่าใด
เพื่อให้เข้าใจวิธีการคำนวณ ลองจินตนาการว่าโยนเหรียญเพียง 4 ครั้ง ฝ่ายใดฝ่ายหนึ่งสามารถหลุดออกไปได้ทุกครั้ง เราถามตัวเองว่า: ความน่าจะเป็นที่จะออก 2 หัวจากการโยน 4 ครั้งเป็นเท่าใด การโยนแต่ละครั้งเป็นอิสระจากกัน ซึ่งหมายความว่าความน่าจะเป็นที่จะได้ชุดค่าผสมใดๆ จะเท่ากับผลคูณของความน่าจะเป็นของผลลัพธ์ที่กำหนดสำหรับการโยนแต่ละครั้ง ให้ O เป็นหัว P เป็นก้อย ตัวอย่างเช่น หนึ่งในชุดค่าผสมที่เหมาะกับเราอาจดูเหมือน OOPP นั่นคือ:

ความน่าจะเป็นของการรวมกันดังกล่าวเท่ากับผลคูณของความน่าจะเป็นที่จะออกหัว 2 ครั้ง และความน่าจะเป็นอีก 2 ข้อที่จะไม่ออกหัว (เหตุการณ์ย้อนกลับคำนวณเป็น 1 หน้า), เช่น. 0.5×0.5×(1-0.5)×(1-0.5)=0.0625. นี่คือความน่าจะเป็นของหนึ่งในชุดค่าผสมที่เหมาะกับเรา แต่คำถามเกี่ยวกับจำนวนนกอินทรีทั้งหมด ไม่ใช่ลำดับเฉพาะใดๆ จากนั้นคุณต้องเพิ่มความน่าจะเป็นของชุดค่าผสมทั้งหมดที่มีนกอินทรี 2 ตัวพอดี เป็นที่ชัดเจนว่าเหมือนกันทั้งหมด (ผลิตภัณฑ์ไม่เปลี่ยนแปลงจากการเปลี่ยนสถานที่ของปัจจัย) ดังนั้นคุณต้องคำนวณจำนวนแล้วคูณด้วยความน่าจะเป็นของชุดค่าผสมดังกล่าว ลองนับรวมทั้งหมด 4 ครั้งของ 2 อีเกิล: RROO, RORO, ROOR, ORRO, OROR, OORR 6 ตัวเลือกเท่านั้น

ดังนั้น ความน่าจะเป็นที่ต้องการในการออก 2 หัวหลังจากการโยน 4 ครั้งคือ 6×0.0625=0.375
อย่างไรก็ตาม การนับด้วยวิธีนี้เป็นเรื่องที่น่าเบื่อ สำหรับ 10 เหรียญจะเป็นการยากมากที่จะได้รับตัวเลือกทั้งหมดโดยใช้กำลังดุร้าย ดังนั้นคนฉลาดจึงคิดค้นสูตรเมื่อนานมาแล้วโดยใช้ความช่วยเหลือในการคำนวณจำนวนชุดค่าผสมต่างๆ นองค์ประกอบโดย เค, ที่ไหน นคือจำนวนองค์ประกอบทั้งหมด เคคือจำนวนองค์ประกอบที่มีการคำนวณตัวเลือกการจัดเรียง สูตรผสมของ นองค์ประกอบโดย เคเป็น:
![]()
สิ่งที่คล้ายกันเกิดขึ้นในส่วน combinatorics ฉันส่งทุกคนที่ต้องการพัฒนาความรู้ไปที่นั่น อย่างไรก็ตาม ชื่อของการแจกแจงแบบทวินาม (สูตรข้างต้นคือค่าสัมประสิทธิ์ในการขยายตัวของนิวตันทวินาม)
สูตรสำหรับการพิจารณาความน่าจะเป็นสามารถสรุปเป็นตัวเลขได้อย่างง่ายดาย นและ เค. ดังนั้นสูตรการกระจายทวินามจึงมีรูปแบบดังนี้
กล่าวอีกนัยหนึ่ง: คูณจำนวนชุดค่าผสมที่ตรงกันด้วยความน่าจะเป็นของชุดค่าผสมใดชุดหนึ่ง
สำหรับ ใช้งานได้จริงแค่รู้สูตรการแจกแจงแบบทวินามก็เพียงพอแล้ว และคุณอาจไม่รู้ด้วยซ้ำ - ด้านล่างนี้เป็นวิธีกำหนดความน่าจะเป็นโดยใช้ Excel แต่จะดีกว่าที่จะรู้
ลองใช้สูตรนี้เพื่อคำนวณความน่าจะเป็นที่จะได้ 40 หัวในการทอย 100 ครั้ง:
หรือเพียง 1.08%. สำหรับการเปรียบเทียบ ความน่าจะเป็นของความคาดหวังทางคณิตศาสตร์ของการทดลองนี้ นั่นคือ 50 หัว คือ 7.96% ความน่าจะเป็นสูงสุดของค่าทวินามเป็นของค่าที่สอดคล้องกับความคาดหวังทางคณิตศาสตร์
การคำนวณความน่าจะเป็นของการแจกแจงแบบทวินามใน Excel
หากคุณใช้เพียงกระดาษและเครื่องคิดเลข ให้คำนวณโดยใช้สูตร การกระจายทวินามแม้จะไม่มีอินทิกรัล แต่ก็ค่อนข้างยาก ตัวอย่างเช่น ค่า 100! - มีมากกว่า 150 ตัวอักษร เป็นไปไม่ได้ที่จะคำนวณด้วยตนเอง ก่อนหน้านี้และแม้แต่ตอนนี้ มีการใช้สูตรโดยประมาณในการคำนวณปริมาณดังกล่าว ในขณะนี้ ขอแนะนำให้ใช้ซอฟต์แวร์พิเศษ เช่น MS Excel ดังนั้น ผู้ใช้ทุกคน (แม้แต่นักมนุษยนิยมจากการศึกษา) สามารถคำนวณความน่าจะเป็นของค่าของตัวแปรสุ่มแบบกระจายทวินามได้อย่างง่ายดาย
ในการรวมเนื้อหา เราจะใช้ Excel เป็นเครื่องคิดเลขปกติในขณะนั้น เช่น ลองทำการคำนวณทีละขั้นตอนโดยใช้สูตรการกระจายทวินาม ลองคำนวณดู เช่น ความน่าจะเป็นที่จะได้ 50 หัว ด้านล่างเป็นภาพขั้นตอนการคำนวณและผลลัพธ์สุดท้าย

อย่างที่คุณเห็น ผลลัพธ์ระดับกลางเป็นสเกลที่ไม่พอดีกับเซลล์ แม้ว่าฟังก์ชันประเภทอย่างง่ายจะถูกใช้ทุกที่: FACTOR (การคำนวณแฟกทอเรียล) POWER (การเพิ่มจำนวนเป็นกำลัง) เช่นกัน เป็นตัวดำเนินการคูณและหาร ยิ่งกว่านั้นการคำนวณนี้ค่อนข้างยุ่งยาก แต่ก็ไม่กะทัดรัดตั้งแต่นั้นมา หลายเซลล์ที่เกี่ยวข้อง และใช่ มันยากที่จะเข้าใจ
โดยทั่วไป Excel มีฟังก์ชันสำเร็จรูปสำหรับคำนวณความน่าจะเป็นของการแจกแจงแบบทวินาม ฟังก์ชันนี้เรียกว่า BINOM.DIST

จำนวนความสำเร็จคือจำนวนการทดลองที่สำเร็จ เรามี 50 รายการ
จำนวนการทดลอง- จำนวนการโยน: 100 ครั้ง
ความน่าจะเป็นของความสำเร็จ– ความน่าจะเป็นที่จะได้แต้มในการโยนหนึ่งครั้งคือ 0.5
อินทิกรัล- ระบุทั้ง 1 หรือ 0 หากเป็น 0 จะคำนวณความน่าจะเป็น พี(B=k); ถ้า 1 ฟังก์ชันการแจกแจงแบบทวินามจะถูกคำนวณ เช่น ผลรวมของความน่าจะเป็นทั้งหมดจาก ข=0ก่อน B=เครวม
เรากดตกลงและเราได้ผลลัพธ์เหมือนกับด้านบน ทุกอย่างถูกคำนวณโดยฟังก์ชันเดียวเท่านั้น

สะดวกสบายมาก เพื่อการทดลอง แทนที่จะใส่พารามิเตอร์สุดท้าย 0 เราใส่ 1 เราได้ 0.5398 ซึ่งหมายความว่าในการโยนเหรียญ 100 ครั้ง ความน่าจะเป็นที่จะออกหัวระหว่าง 0 ถึง 50 คือเกือบ 54% และในตอนแรกดูเหมือนว่าควรจะเป็น 50% โดยทั่วไปแล้วการคำนวณจะทำได้ง่ายและรวดเร็ว
นักวิเคราะห์ที่แท้จริงต้องเข้าใจว่าฟังก์ชันทำงานอย่างไร (การกระจายของมันคืออะไร) ดังนั้นลองคำนวณความน่าจะเป็นสำหรับค่าทั้งหมดตั้งแต่ 0 ถึง 100 นั่นคือลองถามตัวเองว่า: ความน่าจะเป็นที่ไม่มีนกอินทรีตัวเดียวจะตกลงมาคืออะไร ว่านกอินทรี 1 ตัวจะตก 2, 3 , 50, 90 หรือ 100 ตัว การคำนวณแสดงในภาพเคลื่อนไหวในตัวเองต่อไปนี้ เส้นสีน้ำเงินคือการกระจายตัวแบบทวินาม จุดสีแดงคือความน่าจะเป็นสำหรับจำนวนเฉพาะของความสำเร็จ k

บางคนอาจถามว่า การแจกแจงแบบทวินามไม่เหมือนกับ... ใช่ คล้ายกันมาก แม้แต่เดอมัวร์ (ในปี ค.ศ. 1733) ก็กล่าวว่าวิธีการแจกแจงแบบทวินามด้วยกลุ่มตัวอย่างจำนวนมาก (ผมไม่รู้ว่าตอนนั้นเรียกว่าอะไร) แต่ก็ไม่มีใครฟังเขา มีเพียงเกาส์และลาปลาซ 60-70 ปีต่อมาเท่านั้นที่ค้นพบอีกครั้งและศึกษากฎการกระจายตัวแบบปกติอย่างรอบคอบ กราฟด้านบนแสดงให้เห็นอย่างชัดเจนว่าความน่าจะเป็นสูงสุดเป็นไปตามความคาดหมายทางคณิตศาสตร์ และเมื่อมันเบี่ยงเบนไป ความน่าจะเป็นก็จะลดลงอย่างรวดเร็ว เช่นเดียวกับกฎหมายปกติ
การกระจายแบบทวินามมีความสำคัญในทางปฏิบัติมาก มันเกิดขึ้นค่อนข้างบ่อย โดยใช้ การคำนวณ Excelดำเนินการได้อย่างรวดเร็วและง่ายดาย ดังนั้นอย่าลังเลที่จะใช้มัน
ในเรื่องนี้ฉันขอกล่าวคำอำลาจนกว่าจะมีการประชุมครั้งต่อไป สิ่งที่ดีที่สุดจงมีสุขภาพแข็งแรง!
แน่นอน เมื่อคำนวณฟังก์ชันการแจกแจงแบบสะสม เราควรใช้ความสัมพันธ์ที่กล่าวถึงระหว่างการแจกแจงแบบทวินามและการแจกแจงแบบเบต้า วิธีนี้ดีกว่าการบวกโดยตรงเมื่อ n > 10
ในตำราคลาสสิกเกี่ยวกับสถิติ เพื่อให้ได้ค่าของการแจกแจงแบบทวินาม มักแนะนำให้ใช้สูตรตามทฤษฎีบทจำกัด (เช่น สูตร Moivre-Laplace) ควรสังเกตว่า จากมุมมองการคำนวณอย่างหมดจดค่าของทฤษฎีบทเหล่านี้มีค่าใกล้เคียงกับศูนย์ โดยเฉพาะอย่างยิ่งในปัจจุบัน เมื่อมีคอมพิวเตอร์ที่มีประสิทธิภาพในเกือบทุกโต๊ะ ข้อเสียเปรียบหลักของการประมาณข้างต้นคือความแม่นยำไม่เพียงพออย่างสมบูรณ์สำหรับค่า n ทั่วไปสำหรับแอปพลิเคชันส่วนใหญ่ ข้อเสียไม่น้อยไปกว่ากันคือการไม่มีคำแนะนำที่ชัดเจนเกี่ยวกับการบังคับใช้ของการประมาณหนึ่งหรืออย่างอื่น (เฉพาะสูตรซีมโทติคเท่านั้นที่มีให้ในข้อความมาตรฐาน ไม่ได้มาพร้อมกับการประมาณค่าที่แม่นยำ ดังนั้นจึงมีประโยชน์น้อย) ฉันจะบอกว่าทั้งสองสูตรใช้ได้กับ n เท่านั้น< 200 и для совсем грубых, ориентировочных расчетов, причем делаемых “вручную” с помощью статистических таблиц. А вот связь между биномиальным распределением и бета-распределением позволяет вычислять биномиальное распределение достаточно экономно.
ฉันไม่พิจารณาปัญหาในการค้นหาควอนไทล์ที่นี่: สำหรับการแจกแจงแบบไม่ต่อเนื่องมันเป็นเรื่องเล็กน้อยและในปัญหาเหล่านั้นที่การแจกแจงดังกล่าวเกิดขึ้นตามกฎแล้วจะไม่เกี่ยวข้องกัน หากยังต้องการปริมาณ ฉันแนะนำให้จัดรูปแบบปัญหาในลักษณะที่ทำงานกับค่า p (ความสำคัญที่สังเกตได้) นี่คือตัวอย่าง: เมื่อใช้อัลกอริธึมการแจงนับ ในแต่ละขั้นตอนจำเป็นต้องตรวจสอบ สมมติฐานทางสถิติเกี่ยวกับตัวแปรสุ่มทวินาม ตามแนวทางดั้งเดิม ในแต่ละขั้นตอนจำเป็นต้องคำนวณสถิติของเกณฑ์และเปรียบเทียบค่ากับขอบเขตของชุดวิกฤต อย่างไรก็ตาม เนื่องจากอัลกอริทึมเป็นแบบแจกแจง จึงจำเป็นต้องกำหนดขอบเขตของชุดวิกฤตในแต่ละครั้งใหม่ (หลังจากนั้น ขนาดตัวอย่างจะเปลี่ยนจากขั้นหนึ่งไปอีกขั้นหนึ่ง) ซึ่งเพิ่มต้นทุนด้านเวลาอย่างไม่เกิดผล วิธีการที่ทันสมัยแนะนำให้คำนวณนัยสำคัญที่สังเกตได้และเปรียบเทียบกับ ระดับความเชื่อมั่นประหยัดในการค้นหาควอนไทล์
ดังนั้น โค้ดต่อไปนี้จะไม่คำนวณฟังก์ชันผกผัน แต่ให้ฟังก์ชัน rev_binomialDF แทน ซึ่งจะคำนวณความน่าจะเป็น p ของความสำเร็จในการทดลองครั้งเดียวโดยพิจารณาจากจำนวน n ของการทดลอง จำนวน m ของความสำเร็จในการทดลองเหล่านั้น และค่า y ของความน่าจะเป็นที่จะประสบความสำเร็จเหล่านี้ สิ่งนี้ใช้ความสัมพันธ์ดังกล่าวข้างต้นระหว่างการแจกแจงทวินามและเบต้า
ในความเป็นจริง ฟังก์ชันนี้ช่วยให้คุณได้รับขอบเขตของช่วงความเชื่อมั่น อันที่จริง สมมติว่าเราประสบความสำเร็จในการทดลองทวินาม n ครั้ง อย่างที่คุณทราบขอบซ้ายของสองด้าน ช่วงความมั่นใจสำหรับพารามิเตอร์ p ที่มีระดับความเชื่อมั่นเป็น 0 ถ้า m = 0 และ for คือคำตอบของสมการ  . ในทำนองเดียวกัน ขอบเขตด้านขวาคือ 1 ถ้า m = n และ for คือคำตอบของสมการ
. ในทำนองเดียวกัน ขอบเขตด้านขวาคือ 1 ถ้า m = n และ for คือคำตอบของสมการ  . นี่ก็หมายความว่าเพื่อที่จะหาขอบเขตด้านซ้าย เราต้องแก้สมการ
. นี่ก็หมายความว่าเพื่อที่จะหาขอบเขตด้านซ้าย เราต้องแก้สมการ  และเพื่อค้นหาสมการที่ถูกต้อง
และเพื่อค้นหาสมการที่ถูกต้อง  . ซึ่งแก้ไขได้ในฟังก์ชัน binom_leftCI และ binom_rightCI ซึ่งจะคืนค่าขอบเขตบนและล่างของช่วงความเชื่อมั่นสองด้านตามลำดับ
. ซึ่งแก้ไขได้ในฟังก์ชัน binom_leftCI และ binom_rightCI ซึ่งจะคืนค่าขอบเขตบนและล่างของช่วงความเชื่อมั่นสองด้านตามลำดับ
ฉันต้องการทราบว่าหากไม่ต้องการความแม่นยำอย่างเหลือเชื่อสำหรับ n ที่ใหญ่เพียงพอคุณสามารถใช้ค่าประมาณต่อไปนี้ [B.L. van der Waerden สถิติทางคณิตศาสตร์ M: IL, 1960, ช. 2 วินาที 7]:  โดยที่ g คือควอไทล์ของการแจกแจงแบบปกติ ค่าของการประมาณนี้คือมีการประมาณแบบง่ายๆ ที่ให้คุณคำนวณปริมาณของการแจกแจงแบบปกติ (ดูข้อความเกี่ยวกับการคำนวณการแจกแจงแบบปกติและส่วนที่เกี่ยวข้องของข้อมูลอ้างอิงนี้) ในทางปฏิบัติของฉัน (ส่วนใหญ่สำหรับ n > 100) การประมาณนี้ให้ตัวเลขประมาณ 3-4 หลักซึ่งตามกฎแล้วค่อนข้างเพียงพอ
โดยที่ g คือควอไทล์ของการแจกแจงแบบปกติ ค่าของการประมาณนี้คือมีการประมาณแบบง่ายๆ ที่ให้คุณคำนวณปริมาณของการแจกแจงแบบปกติ (ดูข้อความเกี่ยวกับการคำนวณการแจกแจงแบบปกติและส่วนที่เกี่ยวข้องของข้อมูลอ้างอิงนี้) ในทางปฏิบัติของฉัน (ส่วนใหญ่สำหรับ n > 100) การประมาณนี้ให้ตัวเลขประมาณ 3-4 หลักซึ่งตามกฎแล้วค่อนข้างเพียงพอ
การคำนวณด้วยรหัสต่อไปนี้ต้องใช้ไฟล์ betaDF.h , betaDF.cpp (ดูหัวข้อการแจกแจงเบต้า) รวมทั้ง logGamma.h , logGamma.cpp (ดูภาคผนวก A) คุณยังสามารถดูตัวอย่างการใช้ฟังก์ชัน
ไฟล์ binomialDF.h
| #ifndef __BINOMIAL_H__ #include "betaDF.h" double binomialDF(การทดลองสองครั้ง ความสำเร็จสองครั้ง double p); /* * ให้มี "การทดลอง" ของการสังเกตอิสระ * ด้วยความน่าจะเป็น "p" ของความสำเร็จในแต่ละข้อ * คำนวณความน่าจะเป็น B(successes|trials,p) ที่จำนวน * ของความสำเร็จอยู่ระหว่าง 0 และ "สำเร็จ" (รวม) */ double rev_binomialDF(การทดลองสองครั้ง, สำเร็จสองครั้ง, double y); /* * ให้ความน่าจะเป็น y ของความสำเร็จอย่างน้อย m * เป็นที่รู้จักในการทดลองของโครงการ Bernoulli ฟังก์ชันค้นหาความน่าจะเป็น p * ของความสำเร็จในการทดลองครั้งเดียว * * ความสัมพันธ์ต่อไปนี้ใช้ในการคำนวณ * * 1 - p = rev_Beta(การทดลอง-ความสำเร็จ| ความสำเร็จ+1, y) */ double binom_leftCI(การทดลองสองครั้ง ความสำเร็จสองครั้ง ระดับสองเท่า); /* ให้มี "การทดลอง" ของการสังเกตอิสระ * โดยมีความน่าจะเป็น "p" ของความสำเร็จในแต่ละ * และจำนวนของความสำเร็จคือ "ความสำเร็จ" * ขอบเขตด้านซ้ายของช่วงความเชื่อมั่นสองด้าน * คำนวณด้วยระดับระดับนัยสำคัญ */ double binom_rightCI(double n, double สำเร็จ, double level); /* ให้มี "การทดลอง" ของการสังเกตอิสระ * โดยมีความน่าจะเป็น "p" ของความสำเร็จในแต่ละ * และจำนวนของความสำเร็จคือ "ความสำเร็จ" * ขอบเขตด้านขวาของช่วงความเชื่อมั่นสองด้าน * คำนวณด้วยระดับระดับนัยสำคัญ */ #endif /* สิ้นสุด #ifndef __BINOMIAL_H__ */ |
ไฟล์ binomialDF.cpp
| /************************************************ **** **********/ /* การกระจายทวินาม */ /**************************** **** ***************************/ #ได้แก่ |
บทที่ 7
กฎเฉพาะของการแจกแจงของตัวแปรสุ่ม
ประเภทของกฎการกระจายตัวของตัวแปรสุ่มแบบไม่ต่อเนื่อง
ให้ตัวแปรสุ่มแยกรับค่า เอ็กซ์ 1 , เอ็กซ์ 2 , …, x n, …. ความน่าจะเป็นของค่าเหล่านี้สามารถคำนวณได้โดยใช้สูตรต่างๆ เช่น โดยใช้ทฤษฎีบทพื้นฐานของทฤษฎีความน่าจะเป็น สูตรของ Bernoulli หรือสูตรอื่นๆ สำหรับสูตรเหล่านี้บางสูตร กฎการกระจายมีชื่อของมันเอง
กฎทั่วไปของการแจกแจงของตัวแปรสุ่มแบบไม่ต่อเนื่อง ได้แก่ กฎการแจกแจงแบบทวินาม เรขาคณิต ไฮเปอร์จีโอเมตริก กฎการกระจายของปัวซอง
กฎการกระจายทวินาม
ปล่อยให้มันผลิต นการพิจารณาคดีโดยอิสระ ซึ่งในแต่ละกรณีอาจมีเหตุการณ์เกิดขึ้นหรือไม่ก็ได้ และ. ความน่าจะเป็นที่จะเกิดเหตุการณ์นี้ในการทดลองแต่ละครั้งมีค่าคงที่ ไม่ขึ้นกับจำนวนการทดลอง และมีค่าเท่ากับ ร=ร(และ). ดังนั้น ความน่าจะเป็นที่เหตุการณ์จะไม่เกิดขึ้น และในการทดสอบแต่ละครั้งก็จะคงที่และเท่ากันด้วย ถาม=1–ร. พิจารณาตัวแปรสุ่ม เอ็กซ์เท่ากับจำนวนครั้งที่เกิดเหตุการณ์ และใน นการทดสอบ เห็นได้ชัดว่าค่าของปริมาณนี้เท่ากับ
เอ็กซ์ 1 = 0 - เหตุการณ์ และใน นไม่ปรากฏการทดสอบ
เอ็กซ์ 2 = 1 – เหตุการณ์ และใน นการทดลองปรากฏขึ้นครั้งเดียว
เอ็กซ์ 3 = 2 - เหตุการณ์ และใน นการทดลองปรากฏขึ้นสองครั้ง
…………………………………………………………..
x n +1 = น- เหตุการณ์ และใน นการทดสอบปรากฏทุกอย่าง นครั้งหนึ่ง.
ความน่าจะเป็นของค่าเหล่านี้สามารถคำนวณได้โดยใช้สูตร Bernoulli (4.1):
ที่ไหน ถึง=0, 1, 2, …,น .
กฎการกระจายทวินาม เอ็กซ์เท่ากับจำนวนความสำเร็จใน นการทดลองของ Bernoulli มีโอกาสสำเร็จ ร.
ดังนั้น ตัวแปรสุ่มแบบไม่ต่อเนื่องมีการแจกแจงทวินาม (หรือกระจายตามกฎทวินาม) หากค่าที่เป็นไปได้คือ 0, 1, 2, …, นและความน่าจะเป็นที่สอดคล้องกันคำนวณโดยสูตร (7.1)
การกระจายทวินามขึ้นอยู่กับสอง พารามิเตอร์ รและ น.
ชุดการกระจายของตัวแปรสุ่มที่กระจายตามกฎทวินามมีรูปแบบ:
| เอ็กซ์ | … | เค | … | น | ||
| ร | | … | … | |
ตัวอย่าง 7.1 . กระสุนสามนัดถูกยิงไปที่เป้าหมาย ความน่าจะเป็นในการยิงแต่ละครั้งคือ 0.4 ค่าสุ่ม เอ็กซ์- จำนวนการโจมตีเป้าหมาย สร้างชุดการกระจาย
การตัดสินใจ. ค่าที่เป็นไปได้ของตัวแปรสุ่ม เอ็กซ์เป็น เอ็กซ์ 1 =0; เอ็กซ์ 2 =1; เอ็กซ์ 3 =2; เอ็กซ์ 4=3. ค้นหาความน่าจะเป็นที่สอดคล้องกันโดยใช้สูตรเบอร์นูลลี เป็นการง่ายที่จะแสดงว่าการใช้สูตรนี้ถูกต้องสมบูรณ์ โปรดทราบว่าความน่าจะเป็นที่จะไม่โดนเป้าหมายด้วยการยิงหนึ่งครั้งจะเท่ากับ 1-0.4=0.6 รับ

ชุดการกระจายมีรูปแบบดังต่อไปนี้:
| เอ็กซ์ | ||||
| ร | 0,216 | 0,432 | 0,288 | 0,064 |
ง่ายต่อการตรวจสอบว่าผลรวมของความน่าจะเป็นทั้งหมดเท่ากับ 1 ตัวแปรสุ่มนั้นเอง เอ็กซ์กระจายตามกฎทวินาม ■
มาหาความคาดหวังทางคณิตศาสตร์และความแปรปรวนของตัวแปรสุ่มที่กระจายตามกฎทวินาม
เมื่อแก้ตัวอย่างที่ 6.5 แสดงให้เห็นว่าการคาดคะเนทางคณิตศาสตร์ของจำนวนเหตุการณ์ที่เกิดขึ้น และใน นการทดสอบอิสระหากมีความเป็นไปได้ที่จะเกิดขึ้น และในการทดสอบแต่ละครั้งมีค่าคงที่และเท่ากัน รเท่ากับ น· ร
ในตัวอย่างนี้ ตัวแปรสุ่มถูกใช้โดยกระจายตามกฎทวินาม ดังนั้นคำตอบของตัวอย่างที่ 6.5 จึงเป็นการพิสูจน์ทฤษฎีบทต่อไปนี้
ทฤษฎีบท 7.1ความคาดหวังทางคณิตศาสตร์ของตัวแปรสุ่มแบบไม่ต่อเนื่องที่กระจายตามกฎทวินามจะเท่ากับผลคูณของจำนวนการทดลองและความน่าจะเป็นของ "ความสำเร็จ" เช่น ม(เอ็กซ์)=น· ร.
ทฤษฎีบท 7.2ความแปรปรวนของตัวแปรสุ่มแบบไม่ต่อเนื่องที่กระจายตามกฎทวินามจะเท่ากับผลคูณของจำนวนการทดลองโดยความน่าจะเป็นของ "ความสำเร็จ" และความน่าจะเป็นของ "ความล้มเหลว" เช่น ง(เอ็กซ์)=npq
ความเบ้และความโด่งของตัวแปรสุ่มที่กระจายตามกฎทวินามถูกกำหนดโดยสูตร
สูตรเหล่านี้สามารถรับได้โดยใช้แนวคิดของช่วงเวลาเริ่มต้นและจุดศูนย์กลาง
กฎการกระจายทวินามรองรับสถานการณ์จริงมากมาย สำหรับค่าขนาดใหญ่ นการแจกแจงแบบทวินามสามารถประมาณได้โดยการแจกแจงแบบอื่น โดยเฉพาะอย่างยิ่งการแจกแจงแบบปัวซอง
การกระจายปัวซอง
ปล่อยให้มี นการทดลองแบร์นูลลีด้วยจำนวนการทดลอง นใหญ่พอ. ก่อนหน้านี้แสดงให้เห็นว่าในกรณีนี้ (ถ้านอกจากนี้ความน่าจะเป็น รการพัฒนา และน้อยมาก) เพื่อหาความน่าจะเป็นของเหตุการณ์ และที่จะปรากฏ ทีในการทดสอบคุณสามารถใช้สูตรปัวซอง (4.9) ถ้าตัวแปรสุ่ม เอ็กซ์หมายถึง จำนวนครั้งของเหตุการณ์ที่เกิดขึ้น และใน นการทดลองของ Bernoulli แล้วความน่าจะเป็นนั้น เอ็กซ์จะเอาความหมาย เคสามารถคำนวณได้ด้วยสูตร
 , (7.2)
, (7.2)
ที่ไหน λ = น.
กฎการกระจายของปัวซองเรียกว่าการกระจายของตัวแปรสุ่มแบบไม่ต่อเนื่อง เอ็กซ์ซึ่งค่าที่เป็นไปได้คือจำนวนเต็มที่ไม่เป็นลบและความน่าจะเป็น พี ทีค่าเหล่านี้พบได้จากสูตร (7.2)
ค่า λ = นเรียกว่า พารามิเตอร์การกระจายปัวซอง
ตัวแปรสุ่มที่กระจายตามกฎของปัวซองสามารถรับค่าได้ไม่จำกัดจำนวน เนื่องจากสำหรับการแจกแจงความน่าจะเป็นนี้ รการเกิดขึ้นของเหตุการณ์ในแต่ละการทดลองมีขนาดเล็ก ดังนั้นการแจกแจงนี้บางครั้งเรียกว่ากฎของปรากฏการณ์ที่หายาก
ชุดการกระจายของตัวแปรสุ่มที่กระจายตามกฎปัวซองมีรูปแบบ
| เอ็กซ์ | … | ที | … | ||||
| ร | … | … |
เป็นการง่ายที่จะตรวจสอบว่าผลรวมของความน่าจะเป็นของแถวที่สองเท่ากับ 1 ในการทำเช่นนี้ เราต้องจำไว้ว่าสามารถขยายฟังก์ชันได้ในอนุกรม Maclaurin ซึ่งจะลู่เข้าหากัน เอ็กซ์. ในกรณีนี้เรามี
 . (7.3)
. (7.3)
ตามที่ระบุไว้ กฎของปัวซองในบางกรณีจะแทนที่กฎทวินาม ตัวอย่างคือตัวแปรสุ่ม เอ็กซ์ค่าที่เท่ากับจำนวนความล้มเหลวในช่วงเวลาหนึ่งโดยใช้อุปกรณ์ทางเทคนิคซ้ำ ๆ สันนิษฐานว่าอุปกรณ์นี้มีความน่าเชื่อถือสูงเช่น ความน่าจะเป็นของความล้มเหลวในแอปพลิเคชันเดียวนั้นน้อยมาก
นอกเหนือจากกรณีที่จำกัดดังกล่าวแล้ว ในทางปฏิบัติยังมีตัวแปรสุ่มที่แจกแจงตามกฎหมายปัวซอง ซึ่งไม่เกี่ยวข้องกับการแจกแจงแบบทวินาม ตัวอย่างเช่น การแจกแจงแบบปัวซองมักใช้เมื่อต้องจัดการกับจำนวนเหตุการณ์ที่เกิดขึ้นในช่วงเวลาหนึ่ง (จำนวนการโทรไปยังชุมสายโทรศัพท์ระหว่างชั่วโมง จำนวนรถที่มาถึงร้านล้างรถในระหว่างวัน จำนวนเครื่องหยุดต่อสัปดาห์ ฯลฯ .) เหตุการณ์ทั้งหมดเหล่านี้ต้องก่อให้เกิดสิ่งที่เรียกว่าการไหลของเหตุการณ์ ซึ่งเป็นหนึ่งในแนวคิดพื้นฐานของทฤษฎีการเข้าคิว พารามิเตอร์ λ แสดงลักษณะความเข้มเฉลี่ยของการไหลของเหตุการณ์
การแจกแจงแบบทวินามเป็นหนึ่งในการแจกแจงความน่าจะเป็นที่สำคัญที่สุดสำหรับตัวแปรสุ่มที่เปลี่ยนแปลงไม่ต่อเนื่อง การแจกแจงแบบทวินามคือการแจกแจงความน่าจะเป็นของจำนวน มเหตุการณ์ และใน นการสังเกตการณ์ที่เป็นอิสระต่อกัน. มักจะมีเหตุการณ์ และเรียกว่า "ความสำเร็จ" ของการสังเกตและเหตุการณ์ตรงกันข้าม - "ความล้มเหลว" แต่การกำหนดนี้มีเงื่อนไขมาก
เงื่อนไขของการแจกแจงแบบทวินาม:
- ดำเนินการทั้งสิ้น นการทดลองซึ่งเหตุการณ์ และอาจเกิดหรือไม่เกิดขึ้นก็ได้
- เหตุการณ์ และในการทดลองแต่ละครั้งสามารถเกิดขึ้นได้ด้วยความน่าจะเป็นที่เท่ากัน หน้า;
- การทดสอบเป็นอิสระต่อกัน
ความน่าจะเป็นที่ใน นเหตุการณ์การทดสอบ และอย่างแน่นอน มครั้ง สามารถคำนวณโดยใช้สูตรเบอร์นูลลี:
![]()
![]() ,
,
ที่ไหน หน้า- ความน่าจะเป็นของเหตุการณ์ที่เกิดขึ้น และ;
ถาม = 1 - หน้าคือความน่าจะเป็นที่เหตุการณ์ตรงข้ามจะเกิดขึ้น
ลองคิดดูสิ เหตุใดการแจกแจงแบบทวินามจึงเกี่ยวข้องกับสูตรเบอร์นูลลีในลักษณะที่อธิบายไว้ข้างต้น . เหตุการณ์ - จำนวนความสำเร็จที่ นการทดสอบแบ่งออกเป็นหลายตัวเลือกซึ่งแต่ละตัวเลือกจะประสบความสำเร็จ มการทดลองและความล้มเหลวเข้ามา น - มการทดสอบ พิจารณาหนึ่งในตัวเลือกเหล่านี้ - ข1 . ตามกฎการบวกความน่าจะเป็น เราคูณความน่าจะเป็นของเหตุการณ์ตรงข้าม:
![]() ,
,
และถ้าเราแสดงว่า ถาม = 1 - หน้า, แล้ว
![]() .
.
ความน่าจะเป็นแบบเดียวกันจะมีตัวเลือกอื่นในข้อใด มความสำเร็จและ น - มความล้มเหลว จำนวนของตัวเลือกดังกล่าวเท่ากับจำนวนวิธีที่เป็นไปได้ นทดสอบรับ มความสำเร็จ.
ผลรวมของความน่าจะเป็นทั้งหมด มหมายเลขเหตุการณ์ และ(ตัวเลขตั้งแต่ 0 ถึง น) เท่ากับหนึ่ง:

โดยแต่ละพจน์เป็นพจน์ของทวินามของนิวตัน ดังนั้นการแจกแจงที่พิจารณาจึงเรียกว่าการแจกแจงแบบทวินาม
ในทางปฏิบัติ บ่อยครั้งจำเป็นต้องคำนวณความน่าจะเป็น "เป็นส่วนใหญ่ มความสำเร็จใน นการทดสอบ" หรือ "อย่างน้อย มความสำเร็จใน นการทดสอบ" สำหรับสิ่งนี้จะใช้สูตรต่อไปนี้
ฟังก์ชันอินทิกรัล นั่นคือ ความน่าจะเป็น ฉ(ม) ว่าใน นเหตุการณ์การสังเกต และจะไม่มาอีกแล้ว มครั้งหนึ่งสามารถคำนวณโดยใช้สูตร:
ในทางกลับกัน ความน่าจะเป็น ฉ(≥ม) ว่าใน นเหตุการณ์การสังเกต และมาอย่างน้อย มครั้งหนึ่งคำนวณโดยสูตร:
บางครั้งก็สะดวกกว่าในการคำนวณความน่าจะเป็นใน นเหตุการณ์การสังเกต และจะไม่มาอีกแล้ว มครั้ง โดยความน่าจะเป็นของเหตุการณ์ตรงกันข้าม:
![]() .
.
สูตรใดที่จะใช้ขึ้นอยู่กับว่าสูตรใดมีคำศัพท์น้อยกว่า
คุณลักษณะของการแจกแจงแบบทวินามคำนวณโดยใช้สูตรต่อไปนี้ .
มูลค่าที่คาดหวัง: .
การกระจายตัว: .
ส่วนเบี่ยงเบนมาตรฐาน: .
การแจกแจงแบบทวินามและการคำนวณใน MS Excel
ความน่าจะเป็นของการแจกแจงแบบทวินาม พี n ( ม) และค่าของฟังก์ชันอินทิกรัล ฉ(ม) สามารถคำนวณได้โดยใช้ฟังก์ชัน MS Excel BINOM.DIST หน้าต่างสำหรับการคำนวณที่เกี่ยวข้องแสดงอยู่ด้านล่าง (คลิกปุ่มซ้ายของเมาส์เพื่อขยาย)
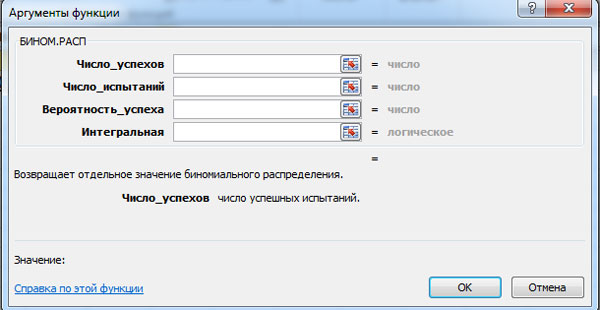
MS Excel ต้องการให้คุณป้อนข้อมูลต่อไปนี้:
- จำนวนความสำเร็จ
- จำนวนการทดสอบ
- ความน่าจะเป็นของความสำเร็จ
- อินทิกรัล - ค่าตรรกะ: 0 - หากคุณต้องการคำนวณความน่าจะเป็น พี n ( ม) และ 1 - ถ้าความน่าจะเป็น ฉ(ม).
ตัวอย่างที่ 1ผู้จัดการของบริษัทได้สรุปข้อมูลเกี่ยวกับจำนวนกล้องที่ขายในช่วง 100 วันที่ผ่านมา ตารางสรุปข้อมูลและคำนวณความน่าจะเป็นที่จะขายกล้องจำนวนหนึ่งต่อวัน
วันจบลงด้วยกำไรหากขายกล้องได้ 13 ตัวขึ้นไป ความน่าจะเป็นที่วันนั้นจะได้กำไร:
![]()
ความน่าจะเป็นที่วันนั้นจะทำงานโดยไม่มีกำไร:
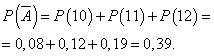
ปล่อยให้ความน่าจะเป็นที่วันนั้นทำงานได้โดยมีกำไรคงที่และเท่ากับ 0.61 และจำนวนกล้องที่ขายต่อวันไม่ได้ขึ้นอยู่กับวัน จากนั้นคุณสามารถใช้การแจกแจงแบบทวินามโดยที่เหตุการณ์ และ- วันจะมีกำไร - ไม่มีกำไร
ความน่าจะเป็นที่ใน 6 วันทั้งหมดจะได้กำไร:
![]() .
.
เราได้ผลลัพธ์เดียวกันโดยใช้ฟังก์ชัน MS Excel BINOM.DIST (ค่าของค่าอินทิกรัลคือ 0):
พี 6 (6 ) = BINOM.DIST(6; 6; 0.61; 0) = 0.052
ความน่าจะเป็นที่จาก 6 วัน 4 วันหรือมากกว่าจะทำงานโดยมีกำไร:
ที่ไหน ![]() ,
,
![]() ,
,
การใช้ฟังก์ชัน MS Excel BINOM.DIST เราคำนวณความน่าจะเป็นที่ภายใน 6 วันจะทำกำไรได้ไม่เกิน 3 วัน (ค่าของค่าอินทิกรัลคือ 1):
พี 6 (≤3 ) = BINOM.DIST(3, 6, 0.61, 1) = 0.435
ความน่าจะเป็นที่ใน 6 วันทั้งหมดจะจบลงด้วยความสูญเสีย:
![]() ,
,
เราคำนวณตัวบ่งชี้เดียวกันโดยใช้ฟังก์ชัน MS Excel BINOM.DIST:
พี 6 (0 ) = BINOM.DIST(0; 6; 0.61; 0) = 0.0035
แก้ปัญหาด้วยตัวคุณเองแล้วดูวิธีแก้ปัญหา
ตัวอย่างที่ 2โกศมีลูกบอลสีขาว 2 ลูกและสีดำ 3 ลูก ลูกบอลถูกนำออกจากโกศ, สีถูกตั้งค่าแล้วใส่กลับเข้าไป พยายามทำซ้ำ 5 ครั้ง จำนวนการปรากฏของลูกบอลสีขาวเป็นตัวแปรสุ่มแบบไม่ต่อเนื่อง เอ็กซ์กระจายตามกฎทวินาม เขียนกฎการกระจายของตัวแปรสุ่ม กำหนดฐานนิยม ความคาดหวังทางคณิตศาสตร์ และความแปรปรวน
เรายังคงแก้ปัญหาร่วมกัน
ตัวอย่างที่ 3จากบริการจัดส่งไปที่วัตถุ น= 5 จัดส่ง จัดส่งแต่ละคนด้วยความน่าจะเป็น หน้า= 0.3 มาช้าสำหรับวัตถุโดยไม่คำนึงถึงวัตถุอื่นๆ ตัวแปรสุ่มแบบไม่ต่อเนื่อง เอ็กซ์- จำนวนของบริการจัดส่งล่าช้า สร้างชุดการกระจายของตัวแปรสุ่มนี้ ค้นหาความคาดหวังทางคณิตศาสตร์ ความแปรปรวน ส่วนเบี่ยงเบนมาตรฐาน ค้นหาความน่าจะเป็นที่คนส่งของอย่างน้อยสองคนจะมาส่งของช้า
ทฤษฎีความน่าจะเป็นเป็นสิ่งที่มองไม่เห็นในชีวิตของเรา เราไม่ใส่ใจกับมัน แต่ทุกเหตุการณ์ในชีวิตของเรามีความเป็นไปได้ไม่ทางใดก็ทางหนึ่ง เมื่อพิจารณาจากสถานการณ์ที่เป็นไปได้จำนวนมาก จำเป็นที่เราจะต้องพิจารณาว่ามีโอกาสเป็นไปได้มากที่สุดและมีโอกาสน้อยที่สุด สะดวกที่สุดในการวิเคราะห์ข้อมูลที่น่าจะเป็นแบบกราฟิก การกระจายสามารถช่วยเราในเรื่องนี้ ทวินามเป็นหนึ่งในวิธีที่ง่ายที่สุดและแม่นยำที่สุด
ก่อนที่จะดำเนินการโดยตรงกับคณิตศาสตร์และทฤษฎีความน่าจะเป็น ลองคิดดูว่าใครเป็นคนแรกที่คิดการแจกแจงประเภทนี้และประวัติของการพัฒนาเครื่องมือทางคณิตศาสตร์สำหรับแนวคิดนี้คืออะไร
ประวัติศาสตร์
แนวคิดของความน่าจะเป็นเป็นที่รู้จักกันมาตั้งแต่สมัยโบราณ อย่างไรก็ตาม นักคณิตศาสตร์โบราณไม่ได้ให้ความสำคัญกับมันมากนัก และทำได้เพียงวางรากฐานสำหรับทฤษฎีที่ต่อมากลายเป็นทฤษฎีของความน่าจะเป็น พวกเขาสร้างวิธีการเชิงผสมผสานซึ่งช่วยผู้ที่สร้างและพัฒนาทฤษฎีในภายหลังอย่างมาก
ในช่วงครึ่งหลังของศตวรรษที่สิบเจ็ด การก่อตัวของแนวคิดพื้นฐานและวิธีการของทฤษฎีความน่าจะเป็นเริ่มขึ้น นิยามของตัวแปรสุ่ม วิธีการคำนวณความน่าจะเป็นของเหตุการณ์ที่เป็นอิสระและขึ้นอยู่กับเหตุการณ์ที่ซับซ้อนบางอย่างและเรียบง่ายได้รับการแนะนำ ความสนใจในตัวแปรสุ่มและความน่าจะเป็นถูกกำหนดโดยการพนัน: แต่ละคนต้องการทราบว่าโอกาสในการชนะเกมเป็นอย่างไร
ขั้นตอนต่อไปคือการประยุกต์ใช้วิธีการวิเคราะห์ทางคณิตศาสตร์ในทฤษฎีความน่าจะเป็น นักคณิตศาสตร์ที่มีชื่อเสียงเช่น Laplace, Gauss, Poisson และ Bernoulli รับหน้าที่นี้ พวกเขาเป็นผู้ที่พัฒนาสาขาคณิตศาสตร์นี้ไป ระดับใหม่. เจมส์ เบอร์นูลลีเป็นผู้ค้นพบ กฎทวินามการกระจาย. โดยวิธีการที่เราจะค้นพบในภายหลังบนพื้นฐานของการค้นพบนี้มีการสร้างอีกหลายอย่างซึ่งทำให้สามารถสร้างกฎของการแจกแจงแบบปกติและอื่น ๆ อีกมากมาย
ตอนนี้ ก่อนที่เราจะเริ่มอธิบายการแจกแจงแบบทวินาม เราจะรีเฟรชเล็กน้อยในความทรงจำเกี่ยวกับแนวคิดของทฤษฎีความน่าจะเป็น ซึ่งอาจจะลืมไปแล้วจากม้านั่งในโรงเรียน
พื้นฐานของทฤษฎีความน่าจะเป็น
เราจะพิจารณาระบบดังกล่าวซึ่งเป็นไปได้เพียงสองผลลัพธ์: "สำเร็จ" และ "ล้มเหลว" ตัวอย่างนี้เข้าใจได้ง่าย: เราโยนเหรียญโดยเดาว่าก้อยจะหลุดออกมา ความน่าจะเป็นของแต่ละเหตุการณ์ที่เป็นไปได้ (หางตก - "สำเร็จ" ออกหัว - "ไม่สำเร็จ") จะเท่ากับ 50 เปอร์เซ็นต์หากเหรียญมีความสมดุลอย่างสมบูรณ์และไม่มีปัจจัยอื่นที่อาจส่งผลต่อการทดสอบ
มันเป็นเหตุการณ์ที่ง่ายที่สุด แต่ยังมีระบบที่ซับซ้อนซึ่งมีการดำเนินการตามลำดับและความน่าจะเป็นของผลลัพธ์ของการกระทำเหล่านี้จะแตกต่างกัน ตัวอย่างเช่น พิจารณาระบบต่อไปนี้: ในกล่องที่เรามองไม่เห็น มีลูกบอลหกลูกที่เหมือนกันทุกประการ สีน้ำเงิน สามคู่ สีแดง และ ดอกไม้สีขาว. เราต้องสุ่มให้ได้กี่ลูก ดังนั้นการดึงลูกบอลสีขาวลูกหนึ่งออกมาก่อน เราจะลดความน่าจะเป็นที่ลูกถัดไปจะได้ลูกบอลสีขาวหลายเท่า สิ่งนี้เกิดขึ้นเนื่องจากจำนวนของวัตถุในระบบเปลี่ยนไป
ในหัวข้อถัดไป เราจะพิจารณาแนวคิดทางคณิตศาสตร์ที่ซับซ้อนมากขึ้น ซึ่งนำเราเข้าใกล้คำว่า " การแจกแจงแบบปกติ"," การกระจายทวินาม "และอื่น ๆ

องค์ประกอบของสถิติทางคณิตศาสตร์
ในสถิติซึ่งเป็นหนึ่งในขอบเขตของการประยุกต์ใช้ทฤษฎีความน่าจะเป็น มีตัวอย่างมากมายที่ไม่ได้ให้ข้อมูลสำหรับการวิเคราะห์อย่างชัดเจน นั่นคือไม่ใช่ตัวเลข แต่อยู่ในรูปแบบของการแบ่งตามลักษณะเช่นตามเพศ ในการใช้เครื่องมือทางคณิตศาสตร์กับข้อมูลดังกล่าวและสรุปผลจากผลลัพธ์ที่ได้ จำเป็นต้องแปลงข้อมูลเริ่มต้นเป็นรูปแบบตัวเลข ตามกฎแล้ว ในการดำเนินการนี้ ผลลัพธ์ที่เป็นบวกจะได้รับการกำหนดค่าเป็น 1 และค่าที่เป็นลบจะได้รับการกำหนดค่าเป็น 0 ดังนั้นเราจึงได้รับข้อมูลทางสถิติที่สามารถวิเคราะห์ได้โดยใช้วิธีการทางคณิตศาสตร์
ขั้นตอนต่อไปในการทำความเข้าใจว่าการแจกแจงแบบทวินามของตัวแปรสุ่มคือการกำหนดความแปรปรวนของตัวแปรสุ่มและความคาดหวังทางคณิตศาสตร์ เราจะพูดถึงเรื่องนี้ในหัวข้อถัดไป

มูลค่าที่คาดหวัง
ความจริงแล้ว การเข้าใจความคาดหวังทางคณิตศาสตร์ไม่ใช่เรื่องยาก พิจารณาระบบที่มีเหตุการณ์ต่างๆ มากมายที่มีความน่าจะเป็นต่างกัน ความคาดหวังทางคณิตศาสตร์จะเรียกว่าค่าเท่ากับผลรวมของผลคูณของค่าของเหตุการณ์เหล่านี้ (ในรูปแบบทางคณิตศาสตร์ที่เราพูดถึงในส่วนสุดท้าย) และความน่าจะเป็นของการเกิดขึ้น
ความคาดหวังทางคณิตศาสตร์ของการแจกแจงแบบทวินามนั้นคำนวณตามรูปแบบเดียวกัน: เรานำค่าของตัวแปรสุ่มมาคูณกับความน่าจะเป็นของผลลัพธ์ที่เป็นบวก จากนั้นจึงสรุปข้อมูลที่ได้รับสำหรับตัวแปรทั้งหมด สะดวกมากในการนำเสนอข้อมูลเหล่านี้แบบกราฟิก - วิธีนี้จะทำให้รับรู้ความแตกต่างระหว่างความคาดหวังทางคณิตศาสตร์ของค่าต่างๆ ได้ดีขึ้น
ในส่วนถัดไป เราจะบอกคุณเล็กน้อยเกี่ยวกับแนวคิดที่แตกต่าง - ความแปรปรวนของตัวแปรสุ่ม นอกจากนี้ยังเกี่ยวข้องอย่างใกล้ชิดกับแนวคิดเช่นการแจกแจงความน่าจะเป็นแบบทวินาม และเป็นลักษณะเฉพาะ

ความแปรปรวนของการแจกแจงแบบทวินาม
ค่านี้เกี่ยวข้องอย่างใกล้ชิดกับค่าก่อนหน้าและยังระบุลักษณะการกระจายของข้อมูลทางสถิติด้วย มันแสดงถึงค่าเฉลี่ยกำลังสองของการเบี่ยงเบนของค่าจากความคาดหวังทางคณิตศาสตร์ นั่นคือ ความแปรปรวนของตัวแปรสุ่มเป็นผลรวมของผลต่างกำลังสองระหว่างค่าของตัวแปรสุ่มกับตัวแปรสุ่ม ความคาดหวังทางคณิตศาสตร์คูณด้วยความน่าจะเป็นของเหตุการณ์นี้
โดยทั่วไป นี่คือทั้งหมดที่เราต้องรู้เกี่ยวกับความแปรปรวนเพื่อที่จะเข้าใจว่าการแจกแจงความน่าจะเป็นแบบทวินามคืออะไร ตอนนี้เรามาที่หัวข้อหลักของเรา กล่าวคือ สิ่งที่อยู่เบื้องหลังวลีที่ดูค่อนข้างซับซ้อนเช่น "กฎการกระจายทวินาม"

การกระจายทวินาม
ก่อนอื่นมาทำความเข้าใจว่าทำไมการแจกแจงนี้เป็นแบบทวินาม มาจากคำว่า binom คุณอาจเคยได้ยินเกี่ยวกับทวินามของนิวตัน ซึ่งเป็นสูตรที่สามารถใช้เพื่อขยายผลบวกของเลข a และ b สองตัวให้เป็นเลขยกกำลังที่ไม่ใช่ลบของ n
อย่างที่คุณอาจเดาได้แล้ว สูตรทวินามของนิวตันและสูตรการกระจายทวินามเกือบจะเป็นสูตรเดียวกัน ยกเว้นเพียงอย่างเดียวว่าค่าที่สองมีค่าที่ใช้สำหรับปริมาณเฉพาะ และค่าแรกเป็นเพียงเครื่องมือทางคณิตศาสตร์ทั่วไป การใช้งานในทางปฏิบัติอาจแตกต่างกัน
สูตรการกระจาย
ฟังก์ชันการแจกแจงแบบทวินามสามารถเขียนเป็นผลรวมของพจน์ต่อไปนี้:
(n!/(n-k)!k!)*p k *q n-k
ที่นี่ n คือจำนวนของการทดลองสุ่มอิสระ p คือจำนวนของผลลัพธ์ที่สำเร็จ q คือจำนวนของผลลัพธ์ที่ไม่สำเร็จ k คือจำนวนของการทดสอบ (สามารถรับค่าได้ตั้งแต่ 0 ถึง n)! - การกำหนดแฟกทอเรียลซึ่งเป็นฟังก์ชันของตัวเลขซึ่งมีค่าเท่ากับผลคูณของตัวเลขทั้งหมดที่ขึ้นไป (ตัวอย่างเช่น สำหรับตัวเลข 4: 4!=1*2*3*4= 24).
นอกจากนี้ ฟังก์ชันการแจกแจงแบบทวินามสามารถเขียนเป็นฟังก์ชันเบต้าที่ไม่สมบูรณ์ได้ อย่างไรก็ตามนี่เป็นมากกว่านั้น คำจำกัดความที่ซับซ้อนซึ่งใช้เมื่อแก้ปัญหาทางสถิติที่ซับซ้อนเท่านั้น
การแจกแจงแบบทวินาม ตัวอย่างที่เราตรวจสอบข้างต้น เป็นหนึ่งในการกระจายตัวแบบทวินาม สายพันธุ์ที่เรียบง่ายการแจกแจงในทฤษฎีความน่าจะเป็น นอกจากนี้ยังมีการแจกแจงแบบปกติซึ่งเป็นการแจกแจงทวินามประเภทหนึ่ง เป็นวิธีที่ใช้บ่อยที่สุดและง่ายที่สุดในการคำนวณ นอกจากนี้ยังมีการแจกแจงแบร์นูลลี การแจกแจงปัวซอง การแจกแจงแบบมีเงื่อนไข พวกเขาทั้งหมดแสดงลักษณะกราฟิกของความน่าจะเป็นของกระบวนการเฉพาะภายใต้เงื่อนไขที่แตกต่างกัน
ในหัวข้อถัดไป เราจะพิจารณาแง่มุมที่เกี่ยวข้องกับการประยุกต์ใช้เครื่องมือทางคณิตศาสตร์นี้ใน ชีวิตจริง. แน่นอนว่าเมื่อมองแวบแรก ดูเหมือนว่านี่จะเป็นอีกสิ่งหนึ่งทางคณิตศาสตร์ ซึ่งตามปกติแล้วจะไม่พบการใช้งานในชีวิตจริง และโดยทั่วไปแล้วไม่มีใครต้องการ ยกเว้นนักคณิตศาสตร์เอง อย่างไรก็ตามนี่ไม่ใช่กรณี ท้ายที่สุดแล้ว การแจกแจงทุกประเภทและการแสดงภาพกราฟิกนั้นถูกสร้างขึ้นเพื่อวัตถุประสงค์ในทางปฏิบัติเท่านั้น ไม่ใช่ตามความตั้งใจของนักวิทยาศาสตร์

แอปพลิเคชัน
การประยุกต์ใช้การแจกแจงที่สำคัญที่สุดในปัจจุบันคือสถิติ ซึ่งจำเป็นต้องมีการวิเคราะห์ที่ซับซ้อนของข้อมูลจำนวนมาก ตามที่แสดงในทางปฏิบัติ อาร์เรย์ข้อมูลจำนวนมากมีการแจกแจงค่าที่ใกล้เคียงกันโดยประมาณ: ขอบเขตวิกฤตของค่าที่ต่ำมากและค่าที่สูงมาก ตามกฎแล้วจะมีองค์ประกอบน้อยกว่าค่าเฉลี่ย
การวิเคราะห์อาร์เรย์ข้อมูลขนาดใหญ่ไม่เพียงจำเป็นสำหรับสถิติเท่านั้น เป็นสิ่งที่ขาดไม่ได้ เช่น ในวิชาเคมีเชิงฟิสิกส์ ในวิทยาศาสตร์นี้ มีการใช้เพื่อหาปริมาณต่างๆ ที่เกี่ยวข้องกับการสั่นสะเทือนและการเคลื่อนที่แบบสุ่มของอะตอมและโมเลกุล
ในหัวข้อถัดไป เราจะพูดถึงความสำคัญในการใช้งานดังกล่าว แนวคิดทางสถิติเป็นทวินาม การกระจายตัวของตัวแปรสุ่มใน ชีวิตประจำวันสำหรับคุณและฉัน

ทำไมฉันถึงต้องการมัน?
หลายคนถามตัวเองด้วยคำถามนี้เมื่อพูดถึงวิชาคณิตศาสตร์ และอย่างไรก็ตาม คณิตศาสตร์ไม่ได้ถูกเรียกว่าราชินีแห่งวิทยาศาสตร์โดยเปล่าประโยชน์ มันเป็นพื้นฐานของฟิสิกส์ เคมี ชีววิทยา เศรษฐศาสตร์ และในแต่ละศาสตร์เหล่านี้ มีการใช้การแจกแจงบางประเภทด้วย ไม่ว่าจะเป็นการแจกแจงแบบทวินามแบบไม่ต่อเนื่องหรือแบบปกติ ก็ไม่มีความสำคัญ และถ้าเรามองโลกรอบตัวเราอย่างใกล้ชิด เราจะเห็นว่าคณิตศาสตร์ถูกนำมาใช้ทุกที่: ในชีวิตประจำวัน ที่ทำงาน และแม้แต่ความสัมพันธ์ของมนุษย์ก็สามารถนำเสนอในรูปแบบของข้อมูลทางสถิติและวิเคราะห์ได้ (โดยวิธีการนี้ ดำเนินการโดยผู้ที่ทำงานในองค์กรพิเศษที่เกี่ยวข้องกับการรวบรวมข้อมูล)
ตอนนี้เรามาพูดถึงสิ่งที่ต้องทำหากคุณต้องการทราบข้อมูลเพิ่มเติมเกี่ยวกับหัวข้อนี้มากกว่าที่เราได้อธิบายไว้ในบทความนี้
ข้อมูลที่เราให้ไว้ในบทความนี้ยังไม่สมบูรณ์ มีความแตกต่างมากมายเกี่ยวกับรูปแบบการกระจายที่อาจใช้ การแจกแจงทวินามดังที่เราได้ค้นพบแล้วเป็นหนึ่งในประเภทหลักที่ใช้สถิติทางคณิตศาสตร์และทฤษฎีความน่าจะเป็นทั้งหมด
หากคุณสนใจหรือเกี่ยวข้องกับงานของคุณ คุณจำเป็นต้องรู้เพิ่มเติมเกี่ยวกับหัวข้อนี้ คุณจะต้องศึกษาวรรณกรรมเฉพาะทาง คุณควรเริ่มต้นด้วยหลักสูตรมหาวิทยาลัยในการวิเคราะห์ทางคณิตศาสตร์และไปที่ส่วนทฤษฎีความน่าจะเป็น นอกจากนี้ ความรู้ในสาขาอนุกรมจะเป็นประโยชน์ เพราะการแจกแจงความน่าจะเป็นแบบทวินามนั้นไม่มีอะไรมากไปกว่าชุดของพจน์ที่ต่อเนื่องกัน
บทสรุป
ก่อนจบบทความ เราขอบอกอีกสิ่งหนึ่งที่น่าสนใจ มันเกี่ยวข้องโดยตรงกับหัวข้อของบทความของเราและคณิตศาสตร์ทั้งหมดโดยทั่วไป
หลายคนบอกว่าคณิตศาสตร์เป็นวิทยาศาสตร์ที่ไร้ประโยชน์ และไม่มีอะไรที่พวกเขาเรียนในโรงเรียนที่เป็นประโยชน์สำหรับพวกเขา แต่ความรู้ไม่เคยฟุ่มเฟือยและหากบางสิ่งไม่เป็นประโยชน์กับคุณในชีวิตนั่นหมายความว่าคุณจำไม่ได้ หากคุณมีความรู้ พวกเขาสามารถช่วยคุณได้ แต่ถ้าคุณไม่มี คุณก็ไม่สามารถคาดหวังความช่วยเหลือจากพวกเขาได้
ดังนั้นเราจึงตรวจสอบแนวคิดของการแจกแจงทวินามและคำจำกัดความทั้งหมดที่เกี่ยวข้องกับมัน และพูดคุยเกี่ยวกับวิธีการใช้มันในชีวิตของเรา



